one,
RCU usage
The most common purpose of the RCU is to replace the existing mechanism as follows:
Read-write lock
Restricted reference counting mechanism
Batch reference counting mechanism
Poor version of garbage collector
Existence guarantee
Type-safe memory
Waiting for the end of things
1.1 RCU is a replacement for read-write locks
In the Linux kernel, the most common use of the RCU is to replace read-write locks. In the early 1990s, Paul implemented a lightweight read-write lock before implementing the universal RCU. Later, for each use envisioned by this lightweight readwrite lock prototype, RCU was eventually used.
The most critical similarity between the RCU and the read-write lock is that both can perform the read-end critical section in parallel. In fact, in some cases, it is entirely possible to replace the RCU's API with the corresponding read-write lock API, and vice versa.
The advantages of RCU are: performance, no deadlock, and good real-time latency. Of course, RCU also has some disadvantages. For example, readers and updaters can execute concurrently. Low-priority RCU readers can also block high-priority threads that are waiting for the grace period to end. The grace period delay may reach several milliseconds.
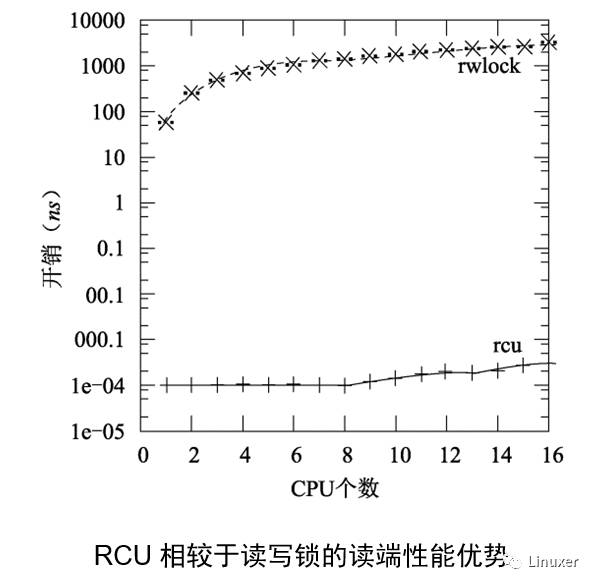
The above figure is not a bit strange, RCU read side delay is actually less than a CPU cycle? This is not a joke, because in some implementations (for example, server Linux), the RCU reader is completely empty. Of course, in such an implementation, it may contain a compiling barrier, and so it will have a little effect on performance.
Note that read and write locks are an order of magnitude slower than RCU on a single CPU, and read and write locks are almost two orders of magnitude slower than RCU on 16 CPUs. With the increase in the number of CPUs, the RCU's scalability advantages have become increasingly prominent. It can be said that RCU is almost horizontal expansion, which can be seen in the figure above.
When the kernel configures CONFIG_PREEMPT, the RCU still exceeds the read-write lock by one to three orders of magnitude, as shown in the following figure. Please note that the read-write lock has a steep curve when there are many CPUs.
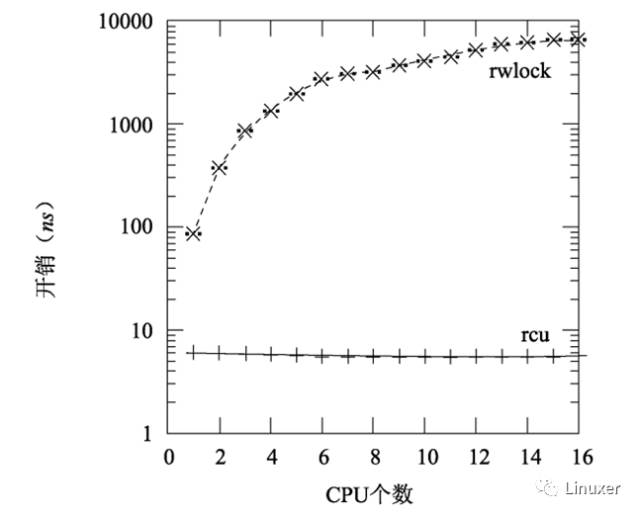
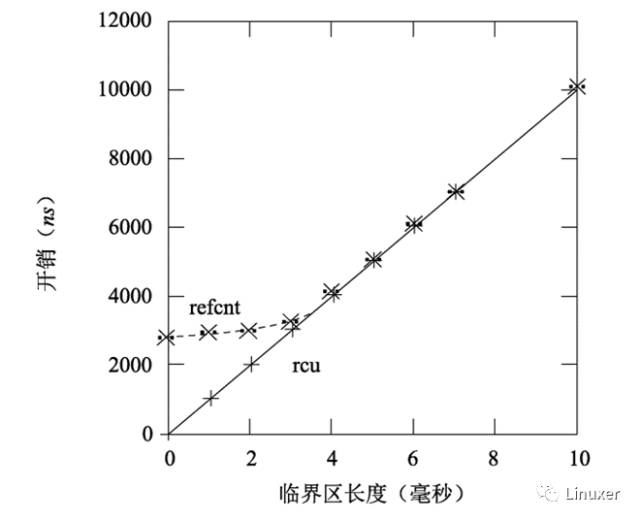
Of course, the length of the critical section in the figure above is 0, which exaggerates the performance disadvantage of the read-write lock. With the increase of critical areas, the performance advantages of RCU are no longer significant. In the figure below, there are 16 CPUs, the y-axis represents the overhead of the read-end primitives, and the x-axis represents the critical region length.
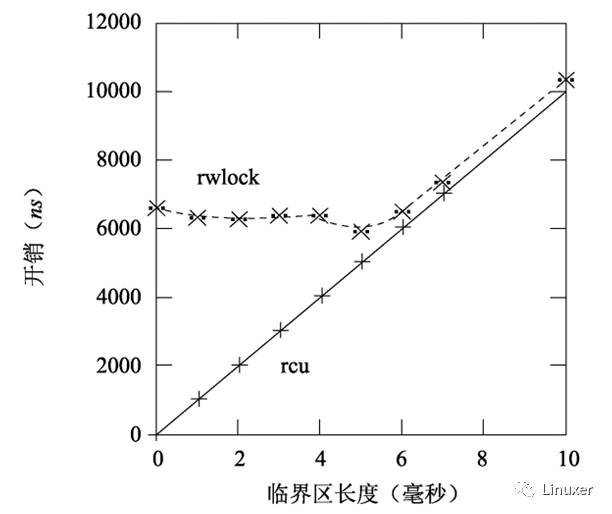
However, in general, the critical region can be completed in a few milliseconds, so in general, the test results are beneficial to the RCU in terms of performance.
In addition, the RCU reader primitive is basically not deadlocked. Because it itself belongs to the category of lock-free programming.
This deadlock-free capability stems from the RCU's read-end primitives being non-blocking, non-spinning, and even without a backwards jump statement, so the execution time of the RCU read-end primitive is fixed. This makes it impossible for the RCU reader primitive to form a deadlock loop.
The ability of RCU readers to avoid deadlocks has an interesting consequence: RCU readers can be arbitrarily upgraded to RCU updaters. Trying this kind of upgrade in read-write locks can cause deadlocks. The code snippet for an RCU reader to updater update is as follows:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, &head, list_field) {
3 do_something_with(p);
4 if (need_update(p)) {
5 spin_lock(my_lock);
6 do_update(p);
7 spin_unlock(&my_lock);
8 }
9 }
10 rcu_read_unlock();
Please note that do_update() is executed under the protection of the lock and is also performed under the protection of the RCU reader.
Another interesting consequence of the RCU free deadlock feature is that the RCU is not affected by the priority reversal problem. For example, a low-priority RCU reader cannot prevent a high-priority RCU updater from acquiring an update-side lock. Similarly, low-priority updaters cannot prevent high-priority RCU readers from entering the RCU read-end critical section.
On the other hand, these primitives have excellent real-time latency because the RCU reader primitives neither spin nor block. There are uncertain real-time delays for spin locks or read-write locks.
However, the RCU is still affected by the more obscure priority reversal issues. For example, a high-priority process that is blocked while waiting for the grace period of the RCU to end will be blocked by the low-priority RCU reader of the -rt kernel. This can be solved with RCU priority promotion.
On the other hand, because RCU readers neither spin nor block, RCU updaters do not have any semantics like rollback or abort, so RCU readers and updaters can execute concurrently. This means that RCU readers may have access to old data, and may find data inconsistent. No matter which of these two issues, it will give read-write locks a chance to come back.
However, surprisingly, in a large number of scenarios, data inconsistency and old data are not a problem. The network routing table is a classic example. Because the update of the route may take a long time to reach the designated system (a few seconds or even several minutes), the system may still send the message to the wrong address within a certain period of time after the new data arrives. Usually, sending a message to the wrong address within a few milliseconds is not a problem.
Simply put, the read-write lock and the RCU provide different guarantees. In read-write locks, any reader starting after the writer is "assured" to see the new value. In contrast, in the RCU, readers who start after the updater finishes are "assured" to see the new value. Readers who finish after the updater starts may see the new value, or they may see the old value, depending on Specific timing.
In real-time RCUs, SRCUs, or QRCUs, preempted readers will prevent the completion of elegant cycles that are in progress, even if high-priority tasks wait for the grace period to complete. Real-time RCUs can avoid this problem by replacing synchronize_rcu() with call_rcu(), or by using RCU priority promotion.
In addition to those "toy" RCU implementations, the RCU grace period may continue for several milliseconds. This makes RCU more suitable for use in the majority of reading data scenarios.
Converting a read-write lock to an RCU is as simple as:



1.2 RCU is a restricted reference counting mechanism
Because the grace period cannot end when the RCU reads the critical section, the RCU primitive can be used like a restricted reference counting mechanism. For example consider the following code fragment:
1 rcu_read_lock(); /* acquire reference. */
2 p = rcu_dereference(head);
3 /* do something with p. */
4 rcu_read_unlock(); /* release reference. */
The rcu_read_lock() primitive can be thought of as taking a reference to p because the corresponding grace period cannot end before the paired rcu_read_unlock(). This reference counting mechanism is limited because we do not allow blocking in the read critical section of the RCU nor do we allow the RCU read critical section of a task to be passed to another task.
Regardless of the above restrictions, the following code can safely remove p:
1 spin_lock(&mylock);
2 p = head;
3 rcu_assign_pointer(head, NULL);
4 spin_unlock(&mylock);
5 /* Wait for all references to be released. */
6 synchronize_rcu();
7 kfree(p);
Of course, RCU can also be combined with traditional reference counting. But why not use reference counting directly? This is due in part to performance, as shown in the figure below, which shows data collected on Intel x86 systems with 16 3GHz CPUs.
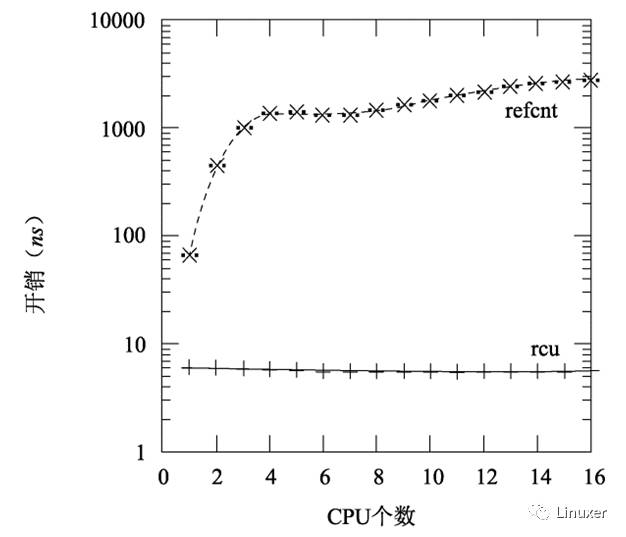
Like the read-write lock, the RCU's performance advantage comes mainly from the shorter critical area, as shown in the figure below.
1.3 RCU is a large-scale reference counting mechanism
As mentioned earlier, traditional reference counting is usually associated with some sort of data structure. However, maintaining a global reference count for a set of data structures typically results in "ping pong" back and forth for cache lines that contain reference counts. This kind of cache line "ping pong" can seriously affect system performance.
In contrast, the lightweight read primitive of the RCU allows the read end to be invoked extremely frequently, but with only negligible performance impact, which makes the RCU a "batch reference counting mechanism" with little performance loss. Sleepable RCUs (SRCUs) can be used when a task needs to hold a reference in a large piece of code. However, a task cannot pass a reference lock reference to another task. For example: Get a reference at the start of an I/O, and then release the reference in the interrupt handler when the corresponding I/O completes.
1.4 RCU is a poor version of the garbage collector
When people started learning RCU, there was a rare sigh that "RCU is a bit like a garbage collector!" This kind of sigh is partly correct, but it will still mislead learning.
Perhaps the best way to think about the relationship between the RCU and the garbage collector (GC) is that the RCU is similar to the GC that automatically determines the timing of recovery, but the RCU is a little different from the GC: (1) The programmer must manually indicate when it can be recycled Specify the data structure, (2) The programmer must manually mark the RCU read-end critical section that can legally hold the reference.
Despite these differences, the degree of similarity between the two is still quite high, at least one theoretical analysis of the RCU's literature has analyzed the similarity between the two.
1.5 RCU is a method of providing a guarantee of existence
Providing existence guarantees through locks has its disadvantages. Similar to locks, if any RCU-protected data element is accessed in the RCU read-end critical section, the data element is guaranteed to exist for the duration of the RCU read-end critical section.
1 int delete(int key)
2 {
3 struct element *p;
4 int b;
5 5
6 b = hashfunction(key);
7 rcu_read_lock();
8 p = rcu_dereference(hashtable[b]);
9 if (p == NULL || p->key != key) {
10 rcu_read_unlock();
11 return 0;
12 }
13 spin_lock(&p->lock);
14 if (hashtable[b] == p && p->key == key) {
15 rcu_read_unlock();
16 hashtable[b] = NULL;
17 spin_unlock(&p->lock);
18 synchronize_rcu();
19 kfree(p);
20 return 1;
twenty one }
22 spin_unlock(&p->lock);
23 rcu_read_unlock();
24 return 0;
25 }
The figure above shows how RCU-based presence guarantees implement per-data element locks by removing elements from the hash table. Line 6 calculates the hash function, and line 7 enters the RCU read-end critical section. If line 9 finds that the corresponding hash of the hash table is empty, or if the data element is not the one we want to delete, line 10 exits the critical section of the RCU reader, and line 11 returns an error.
If line 9 evaluates to false, line 13 gets the spinlock on the update side, and then line 14 checks if the element is still what we want. If so, line 15 exits the RCU read-end critical area, line 16 deletes the found element from the hash table, line 17 releases the lock, and line 18 waits for all previously existing RCU read-end critical sections to exit, 19th. The line releases the newly deleted element, and the last line 20 returns success. If the 14-line decision finds that the element is no longer what we want, then line 22 releases the lock, line 23 exits the RCU read-end critical area, and line 24 returns an error to delete the keyword.
1.6 RCU is a Way to Provide Type-Safe Memory
Many lock-free algorithms do not require that data elements remain exactly the same when referenced by the RCU read-end critical section, as long as the data element type is unchanged. In other words, as long as the data structure type is unchanged, the lock-free algorithm can allow a certain data element to be released and redistributed when referenced by other objects, but the type change is never allowed. This kind of "guarantee" is called "type-safe memory" in the academic literature. It is weaker than the existence guarantee mentioned in the previous section, so it is also difficult to deal with it. The type-safe memory algorithm used in the Linux kernel is the slab buffer, and the cache marked by the SLAB_DESTROY_BY_RCU flag is used to return the freed slab to the system memory through the RCU. During the duration of any existing RCU read-end critical region, using the RCU ensures that all the Slab_DESTROY_BY_RCU tags that are in use and that are in use are still in the slab, with the same type.
Although type-safe, lock-free algorithms are very effective in certain scenarios, it is best to use the existence guarantee as much as possible. After all, simplicity is always better.
1.7 RCU is a way to wait for things to end
One of the strengths of RCU is that it allows you to wait for thousands of different things to end without having to explicitly trace each of them, so you don't need to worry about performance degradation, extension restrictions, complex deadlock scenarios, Memory leaks and other issues of the explicit tracking mechanism itself.
The following shows how to implement interaction with a non-maskable interrupt (NMI) handler, which is extremely difficult if implemented with locks. Proceed as follows:
1. Make changes, for example, the OS reacts to an NMI. Use RCU read primitives in NMI.
2. Wait for all existing read critical sections to exit completely (eg using the synchronize_sched() primitive).
3. The sweeping work, for example, returns a status indicating that the change was completed successfully.
The following is an example of a Linux kernel. In this example, the timer_stop() function uses synchronize_sched() to ensure that all NMI handlers that are being processed have completed before releasing the associated resource.
1 struct profile_buffer {
2 long size;
3 atomic_t entry[0];
4 };
5 static struct profile_buffer *buf = NULL;
6
7 void nmi_profile(unsigned long pcvalue)
8 {
9 struct profile_buffer *p =
Rcu_dereference(buf);
10
11 if (p == NULL)
12 return;
13 if (pcvalue >= p->size)
14 return;
15 atomic_inc(&p->entry[pcvalue]);
16 }
17
18 void nmi_stop(void)
19 {
20 struct profile_buffer *p = buf;
twenty one
22 if (p == NULL)
23 return;
24 rcu_assign_pointer(buf, NULL);
25 synchronize_sched();
26 kfree(p);
27 }
Lines 1 through 4 define the profile_buffer structure, which contains an entry for a size and a variable-length array. Line 5 defines a pointer to profile_buffer, which assumes that the pointer was initialized elsewhere, pointing to the dynamic allocation of memory.
Lines 7-16 define the nmi_profile() function for the NMI interrupt handler function call. This function will not be preempted, nor will it be interrupted by ordinary interrupt handlers. However, the function will still be affected by factors such as cache misses, ECC errors, and other hardware threads being preempted by the same core. Line 9 uses the rcu_dereference() primitive to get the local pointer to profile_buffer. This is done to ensure that the memory is executed sequentially on DEC Alpha. If profile_buffer is not currently allocated, lines 11 and 12 exit, if the parameter pcvalue is out of range, Lines 13 and 14 exit. Otherwise, line 15 adds the value of the profile_buffer entry with the parameter pcvalue as the subscript. Note that the size in the profile_buffer structure ensures that the pcvalue does not exceed the buffer's range, even if the larger buffer is suddenly replaced by a smaller buffer.
Lines 18 to 27 define the nmi_stop() function, and the caller is responsible for exclusive access (such as holding the correct lock). Line 20 gets the profile_buffer pointer. If the buffer is empty, lines 22 and 23 exit. Otherwise, line 24 will set the profile_buffer pointer to NULL (using the rcu_assign_pointer() primitive to guarantee sequential memory access in weakly ordered machines), and line 25 waits for the grace period of the RCU Sched to end, especially waiting for all non-preemptable code to be - Including NMI interrupt handler - end. Once we reach the 26th line, we can guarantee that all nmi_profile() instances that get pointers to the old buffers have returned. You can now safely release the buffer, using the kfree() primitive.
In short, RCU makes profile_buffer dynamic switching easier. You can try atomic operations, or you can use locks to torture yourself. Pay attention to the following point: In most CPU architectures, atomic operations and locks may have loop statements that may be interrupted by the NMI during the loop.
Second, RCU API
2.1 waiting to complete the API family
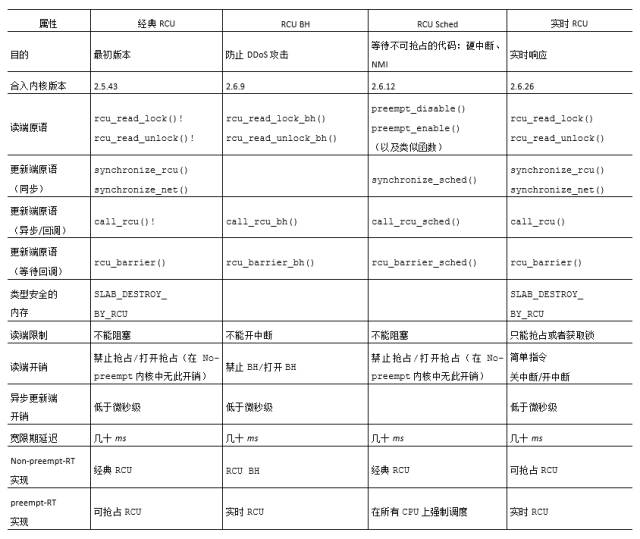
The "RCU Classic" column corresponds to the original implementation of the RCU. The rcu_read_lock() and rcu_read_unlock() primitives indicate the critical region of the RCU read end and can be nested. The corresponding synchronized update primitives synchronize_rcu() and synchronize_net() both wait for the RCU read end critical section currently being executed to exit. Waiting time is called "elegant cycle." The asynchronous update primitive call_rcu() calls the function specified by the parameter after the subsequent grace period. For example, call_rcu(p, f); executes the RCU callback f(p) at the end of the grace period.
To make use of RCU-based type-safe memory, pass SLAB_DESTROY_BY_RCU to kmem_cache_create(). It is important that SLAB_DESTROY_BY_RCU does not prevent kmem_cache_alloc() from immediately reassigning the memory that was just released by kmem_cache_free()! In fact, the data structure protected by the SLAB_DESTROY_BY_RCU tag returned by rcu_dereference may be freed--allocated any number of times, even under rcu_read_lock() protection. However, SLAB_DESTROY_BY_RCU can prevent kmem_cache_free() from completely releasing the data structure it returns to SLAB before the end of the RCU grace period. In a word, although the data element may be freed--reassigned N times, its type remains unchanged.
2.2 Subscriptions and Version Maintenance APIs
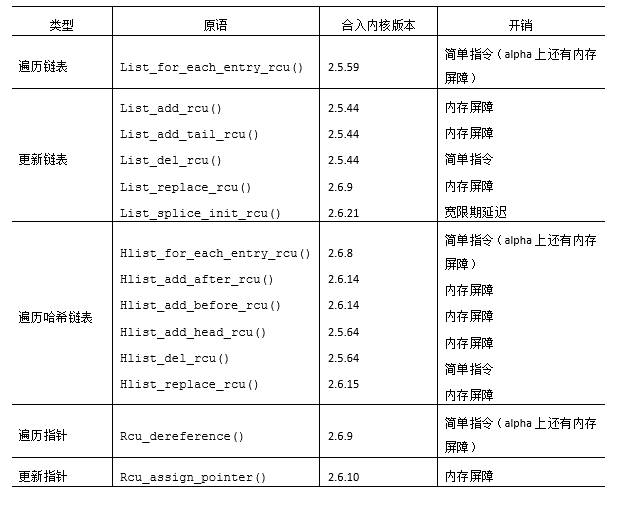
The first type of API in the table acts on Linux's struct list_head circular double-linked list. The list_for_each_entry_rcu() primitive traverses the RCU-protected linked list in a type-safe manner. On non-Alpha platforms, this primitive does not produce or have a very low performance penalty compared to the list_for_each_entry() primitive. The list_add_rcu(), list_add_tail_rcu(), and list_replace_rcu() primitives are all simulations of non-RCU versions, but bring additional memory barrier overhead on weakly sequential machines. The list_del_rcu() primitive is also a non-RCU version of the simulation, but strangely it is slightly faster than the non-RCU version because list_del_rcu() only poisons the prev pointer and list_del() poisons the prev and next pointers at the same time. Finally, the list_splice_init_rcu() primitive is similar to its non-RCU version, but it introduces a complete grace period delay.
The second API in the table directly acts on Linux's struct hlist_head linear hash table. The struct hlist_head is a bit more advanced than structlist_head in that the former requires only a single pointer to the list header, which will save a lot of memory in a large hash table. The relationship between the struct hlist_head primitive in the table and the non-RCU version is the same as the struct list_head primitive.
The last type of API in the table acts directly on pointers, which is useful for creating non-linked list data elements protected by RCUs, such as RCU protected arrays and trees. The rcu_assign_pointer() primitive ensures that any initialization performed prior to assigning a pointer to the weakly ordered machine will be performed sequentially. Similarly, the rcu_dereference() primitive ensures that the code dereferenced by subsequent pointers can see the result of the initialization performed before the corresponding rcu_assign_pointer() on the Alpha CPU.
Strain/flex Reliefs And Grommets
the power Connectors we provide overmolding solutions and modular tooling.
We also offer to the OEM and distributor users a diversified line of strain / flex reliefs and grommets, such as Solid, Solid-Rib, Uniflex, Multiflex, in standard off the shelf or custom designs.
Overmolding the power connectors offers significant opportunities for cable improvements with higher pull strength not available with conventional backshells. Our technical staff is ready to help you from design and prototyping to small production run, assistance, and training.
Our team is ready to help with any of the following power connectors projects: overmolding mini fit jr. and mini-fit sr. connectors, , overmolded cables with micro fit terminations, sabre molded cable asemblies, amp duac overmolded power connectors, mate-n-lock power cables, power connector overmolding services, power connector molding, design and prototype of power cables across the board, small run molded power connecotrs , molded cable manufacturing, overmolding connectors for any power applications
Strain Reliefs And Grommets,Flex Reliefs And Grommets,Cable Strain Reliefs,Cable Flex Reliefs,Cable Grommets,Molded Strain Relief
ETOP WIREHARNESS LIMITED , https://www.wireharness-assembling.com