When humans and animals learn new behaviors, most of them only need to observe once to learn, but it is not so easy to learn robots. With the development of computer vision, current technology allows robots to rely on human body posture detection systems to mimic human movements. But every time you need human "demonstration" is a bit of a hassle, the researchers in this paper have come up with a new way: let the robot imitate learning through a video of only one person.
Previous studies have shown that robots can learn a range of complex skills through observation and demonstration, such as pouring water, playing table tennis, opening drawers, and so on. However, the most effective way for robots to imitate is very different from human learning: robots usually need to receive specific action demonstrations or remote control operations, and humans only need to see others to do it again. In addition, humans can adapt strategies to adapt to new situations based on environmental changes. So, how can we make robots like humans learn by observing third-party demonstrations?
There are two major challenges to getting skills from the original video. First, differences in the appearance and morphology of human presenters and robots lead to systematic domain shifts, ie, correspondence problems. Second, learning from raw visual input usually requires a lot of data, and deep learning vision systems typically use hundreds of thousands to millions of images. In this article, we demonstrate the solution to these two challenges through a single approach based on meta-learning.
Preliminary preparation
Based on previous work or meta-learning, we extend the model meta-learning algorithm to handle the domain transfer between the provided data (ie, human presentation) and the evaluation settings (ie, robot actions).
Meta-learning algorithms can learn new tasks quickly and efficiently. In general, meta-learning can be seen as the function of discovering the structure that exists between tasks. When the model proposes a new task from the metatest set, the model can learn quickly using known structures. The algorithm (MAML) does this by optimizing the initial parameter settings of the deep network. After the meta-training, the learning parameters are fine-tuned based on the data of the new task.
Imitating humans
In this section, we will show that robots mimic the problems of human learning at one time and introduce our test methods. Learning from a video containing humans can be seen as a reasoning problem whose goal is to infer the strategic parameters of the robot, which combines prior knowledge with a small amount of evidence to accomplish the task. In order to learn effectively from a single-person video, we need to include a priori knowledge of the world's rich visual and object understanding.
The test method consists of two stages. In the meta-training stage, we need to use the motion data of humans and robots to acquire prior knowledge and then imitate the action through fast learning. A key part of this approach is that it can be migrated to other meta-learning algorithms. Like the MAML algorithm, we will learn a series of initial parameters, and after several gradient drops, the model can effectively complete new tasks. The algorithm ultimately used for the meta-object can be summarized as:

After the meta-training phase, the prior knowledge learned will be used in the second phase. When the robot mimics the new movements of humans, it is necessary to combine prior knowledge with new human demonstration actions to infer the strategic parameters for solving new tasks. The algorithm is summarized as:

Time series adaptation target learning
In order to learn from people's videos, we need an adaptive goal that can effectively capture relevant information in the video, such as people's intentions and tasks related to the object. Since timing convolution is useful in processing timing and data sequences, we chose to use a convolutional network to represent the adaptation target. The effect is as shown:
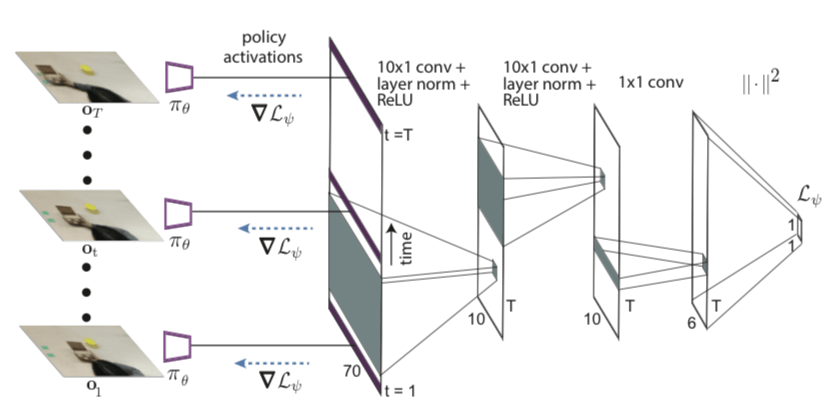
Network Architecture
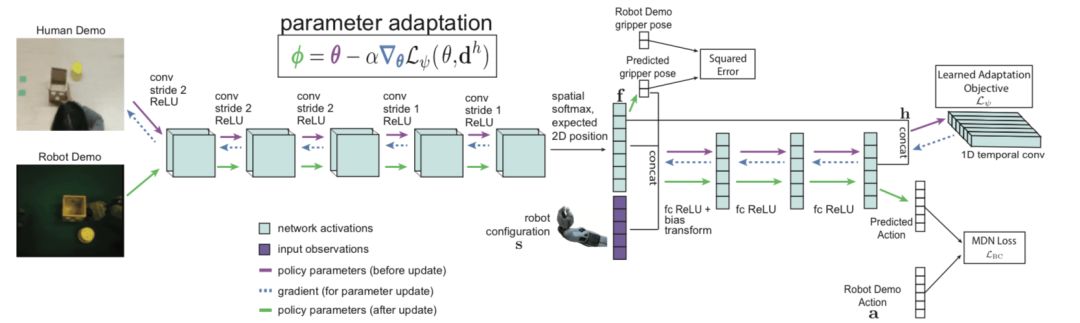
As shown, the network architecture is a convolutional neural network that maps RGB images to motion distributions. The convolutional network begins with several convolutional layers and is then transported into argmax of the channel space, extracting a two-dimensional feature point f for each channel. We then connect these feature points to the robot structure, which includes three non-axis aligned points on the fixture. Then, we pass the connected feature points and robot poses to multiple fully connected layers.
experiment procedure
Our experiment mainly wants to solve three problems:
Can our method effectively learn prior knowledge so that robots can learn to manipulate new objects through video with only one person?
Can our approach allow robots to mimic human movements from a new perspective?
How is the approach we propose different from meta-learning and other methods?
To further understand our approach and its usefulness, we have to evaluate it separately:
How important is the timing adaptation goal?
Can our method be used for multiple robot platforms, as well as meta-training for motion or remote demonstrations?
For evaluation, we performed experiments on a 7-axis PR2 robotic arm and a Sawyer robot.
PR2 experimental process
The first is to use the mechanical arm PR2 to test the action of placing, pushing forward, picking up, etc. The specific process is as follows:

From left to right are: object placement, pushing and picking-down actions. The above row is a human demonstration
The device situation of the whole process is like this:

It was used to shoot a smartphone, and the situation seen from it is this:

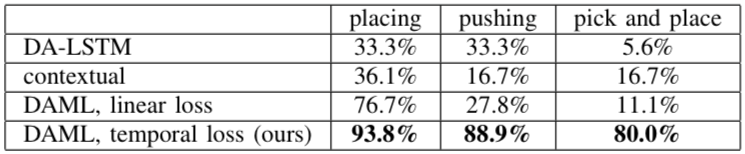
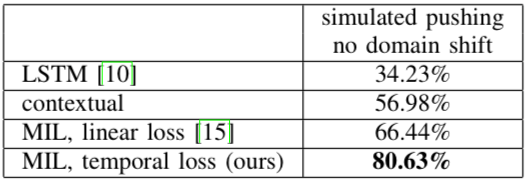
Finally, the assessment of PR2 learning is shown in the table below, and it can be seen that the success rate is much higher than the previous method:
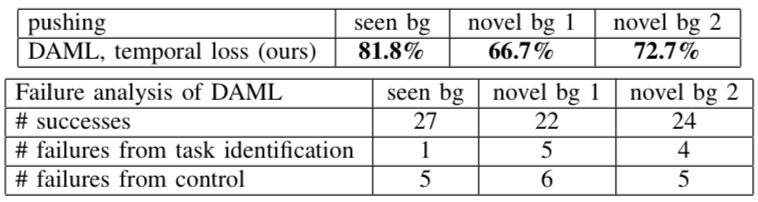
In addition, the researchers also calculated the errors that PR2 made when doing "push":
Sawyer experimental process
Another goal of the experiment was whether our method could be applied to other platforms, so we chose Sawyer with 7 degrees of freedom for verification. Unlike the PR2 experiment, the motion space will be the single command pose of the end effector, and we will use the mean square error as the outer meta target.

In the end, in the experiment using timing adaptation goals, the success rate was 14% higher than that of no use, which proved the importance of merging time information when learning from video.
Limitations of the experiment
Although the results of our work allow robots to learn to manipulate new objects at once from the video, current experiments have not proven that the model can learn new actions at once. I hope that more data and higher performance models will achieve this goal in the future.
The anti-glare technology used in the Matte Protective Film can reduce glare to eliminate eye fatigue, and make it easier to watch under direct light, which is more friendly to your eyes.
In order to let you enjoy it for a long time, the Frosted Screen Protector uses durable military-grade TPU material, which has strong durability and scratch resistance. It protects the screen from unnecessary scratches.
It has good anti-fingerprint ability, sweat will not remain on the screen surface, and it is easy to clean without affecting touch sensitivity or response speed.
The adhesive layer ensures that you stick the Protective Film in a stress-free manner and maintain a strong adhesion without leaving any sticky residue.
If you want to know more about Matte Screen Protector products, please click the product details to view the parameters, models, pictures, prices and other information about Matte Screen Protector.
Whether you are a group or an individual, we will try our best to provide you with accurate and comprehensive information about the Matte Screen Protector!
Matte Screen Protector, Frosted Screen Protector, Matt Screen Protector, Matte Hydrogel Film, Matt Protective Film, Anti-Glare Screen Protector
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.jjtscreenprotector.com