Today we talk about cloud computing, big data and artificial intelligence. These three words are now very hot and they seem to be related to each other.

Generally talking about cloud computing will mention big data, talk about artificial intelligence when it comes to big data, talk about artificial intelligence when it comes to cloud computing... I feel that the three are mutually reinforcing and inseparable.
However, if it is a non-technical person, it may be difficult to understand the relationship between the three, so it is necessary to explain.
The initial goal of cloud computing
We start with cloud computing. The initial goal of cloud computing is to manage resources. The main management areas are computing resources, network resources, and storage resources.
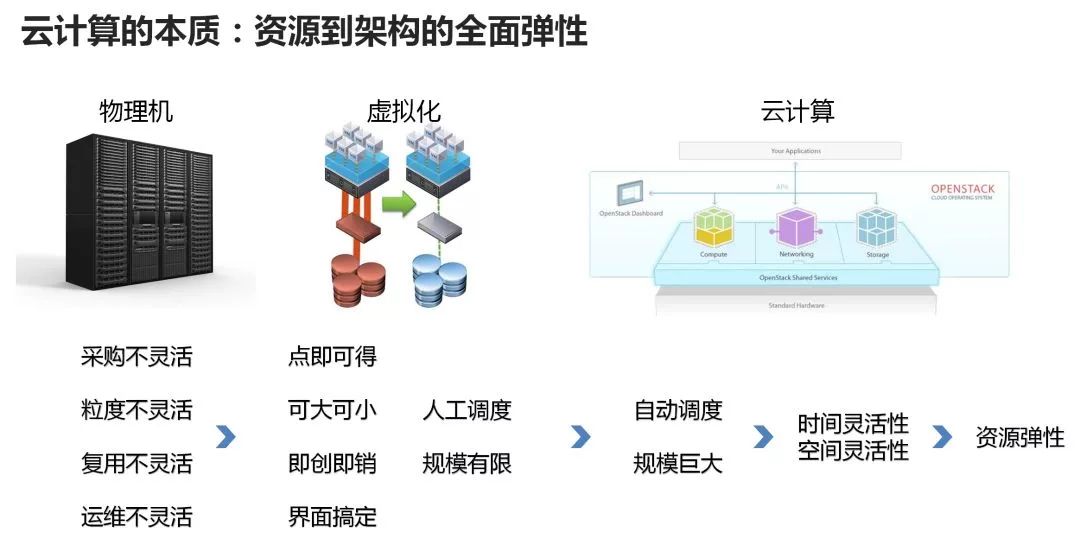
Manage data centers like computers
What is computing, network, storage resources?
For example, if you want to buy a laptop, do you have to care about what kind of CPU this computer is? How much memory? These two are what we call computational resources.
To access the Internet, this computer needs to have a network port that can be plugged in, or a wireless network card that can connect to our home router.
Your home also needs to open a network to operators such as China Unicom, mobile or telecommunications, such as 100M bandwidth. Then the master will get a network cable to your home. The master may help you to configure your router and their company's network connection.
In this way, all your computers, mobile phones and tablets can be accessed through your router. This is network resources.
You may also ask how big a hard disk? In the past, the hard disks were small and the size was 10G. Later, even the 500G, 1T, and 2T hard disks were not new. (1T is 1000G), this is the storage resource.
This is the same for a computer, and it is the same for a data center. Imagine you have a very large room, where you have a lot of servers. These servers also have CPUs, memory, and hard disks, and they also go online via router-like devices.
The question at this time is: How do people operating data centers manage these devices in a unified manner?
Flexibility is when you want to have everything you want.
The goal of management is to achieve two aspects of flexibility. Which two specific aspects?
For example, to understand: For example, someone needs a small computer with only one CPU, 1G RAM, 10G HDD, and 1MB of bandwidth. Can you give it to him?
Like a computer of such a small size, nowadays a random laptop is more powerful than this one, and it is 100M to randomly pull a broadband at home. However, if you go to a cloud computing platform and he wants this resource, there is only one point.
In this case it can achieve two aspects of flexibility:
Time flexibility: Whenever you want to, when you need it, it comes out.
Space flexibility: how much you want. Need a computer with a small space, can be satisfied; need a particularly large space such as cloud disk, the space allocated to everyone by the cloud disk is very large and very large, ready to upload at any time, never use endless, can also be satisfied of.
Space flexibility and time flexibility, which we often say about the elasticity of cloud computing. The solution to this problem of flexibility has experienced a long period of development.
Physical devices are not flexible
The first phase is the period of physical equipment. Customers need a computer during this period, and we will buy one in the data center.
The physical equipment is certainly getting more and more cattle:
For example, the server, memory is a hundred G memory.
For example, a network device can have tens or even hundreds of Gigabits of bandwidth on one port.
For example, storage is at least at the PB level in the data center (one P is 1000 T and one T is 1000 G).
However, physical devices do not have good flexibility:
The first is that it lacks time flexibility. I can't reach when I want to. For example, to buy a server, buy a computer, have to purchase time.
If a user suddenly tells a cloud vendor that he wants to open a computer and use a physical server, then it would be difficult to purchase it. A good relationship with a supplier may take a week, and a supplier-general relationship may require a purchase for a month.
The user waited a long time for the computer to be in place. At this time, the user also logged in to slowly start deploying his application. The time flexibility is very poor.
The second is that its spatial flexibility does not work either. For example, the user mentioned above needs a very small computer, but now there is such a small computer model? Can not buy a small machine to meet the user's only one G's memory, 80G hard drive.
However, if you buy a big one, you will need to pay more to the user because the computer is large. However, the user needs to use only a small amount of money, so it is very embarrassing to pay more.
Virtualization is much more flexible
Someone just thought of a solution. The first method is virtualization. Isn't the user just a small computer?
The physical equipment in the data center is very powerful. I can virtualize a small piece of it from the physical CPU, memory, and hard disk to the customer. At the same time, I can virtualize a small piece to other customers.
Each customer can only see their own small piece, but in fact each customer uses a small piece of the entire large device.
Virtualization technology makes different customers' computers appear to be isolated. That is, I looked at it like this piece of disk is mine, you look at this piece of disk is yours, but the actual situation may be my 10G and your 10G is on the same large and large storage.
And if the physical devices are all ready in advance, virtualizing the software out of a computer is very fast and can be solved in a matter of minutes. So to create a computer on any cloud, it came out in a few minutes. That is the reason.
This space flexibility and time flexibility are basically solved.
Making Money and Feelings in the Virtual World
In the virtualization phase, the most popular company is VMware. It is an early company to realize virtualization technology and can realize the virtualization of computing, network and storage.
This company is very good, the performance is very good, the virtualization software is selling very well, earning a lot of money, and then let EMC (the world's top 500, the first brand of storage vendors) to buy.
But there are still many people in this world who have feelings, especially programmers. How do people with feelings like to do things? Open source.
Many softwares in the world have closed source and open source. Source is source code. That is to say, a certain software does well, everyone loves to use, but the code of this software is closed by me, only my company knows, other people do not know.
If other people want to use this software, they must pay me. This is called closed source. However, there are always some people in the world who cannot afford to use their money to make a profit. Daniels think that this technique you will be able to me; you can develop it, and I can.
When I developed it, I didn't collect any money. I used the code to share it with everyone. Whoever uses the world can do it. All people can enjoy the benefits. This is called open source.
For example, the latest Tim Berners Lee is a very emotional person. In 2017, he won the 2016 Turing Award for “Inventing the World Wide Web, the First Browser, and the Basic Protocols and Algorithms that Make the World Wide Web Extensible.â€
The Turing Award is the Nobel Prize in computer science. However, what he admires most is that he has made free use of the World Wide Web, which is our common WWW technology, free of charge.
We must thank him for all his actions on the Internet. If he uses this technology to collect money, he should be almost as rich as Bill Gates.
There are many examples of open source and closed source. For example, if you have Windows in a closed source world, you have to pay Microsoft for Windows. In the open source world, Linux appears.
Bill Gates made a lot of money by relying on Windows, Office, and other closed-source software. It was called the world’s richest man, and Daniel had developed another operating system, Linux.
Many people may not have heard of Linux. Many programs running on the back-end server are on Linux. For example, everyone enjoys the double eleven. Whether it is Taobao, Jingdong, Koala, etc. On Linux.
Again, Apple has Android. Apple's market value is very high, but we can't see the code of Apple's system. So Big Bull wrote Android operating system.
So everyone can see that almost all other mobile phone manufacturers have Android installed. The reason is that Apple's system is not open source, and everyone can use Android system.
In virtualization software too, with VMware, this software is very expensive. Then there are two open source virtualization software written by Daniel. One is called Xen and the other is called KVM. If you don't do technology, you can ignore these two names, but it will be mentioned later.
Virtualized semi-automatic and fully automated cloud computing
To say that virtualization software solves the problem of flexibility, it is not entirely correct. Because virtualization software generally creates a virtual computer, it is necessary to manually specify on which physical machine the virtual computer is placed.
This process may also require more complex manual configuration. Therefore, the use of VMware's virtualization software requires a very good certificate, and the person who can get this certificate has a very high salary, and its complexity is also visible.
Therefore, the cluster size of physical machines that can only be managed by virtualized software is not particularly large. Generally, it is in the range of dozens, dozens, and hundreds.
This aspect will affect the time flexibility: Although the time to virtualize a computer is very short, but with the expansion of the scale of the cluster, the process of manual configuration becomes more and more complex and more and more time-consuming.
On the other hand, it also influences space flexibility: When the number of users is large, the cluster size is still far from the extent to which it is desired. It is very likely that this resource will soon be used up and it will have to be purchased.
Therefore, with the increasing size of the clusters, basically thousands of companies have started, tens of thousands or even tens of millions. If you look at BAT, including Netease, Google, Amazon, the number of servers are all scary.
It is almost impossible for so many machines to rely on people to choose a place to put this virtualized computer and do the corresponding configuration, or need the machine to do this thing.
People have invented various algorithms to do this. The name of the algorithm is called the scheduler.
In layman's terms, there is a dispatch center. Thousands of machines are in a pool. No matter how many CPUs, memory, or hard disks the user needs, the dispatch center will automatically find a place in the big pool that can meet user needs. The virtual computer is started up and configured so that the user can use it directly.
This phase we call pooling or clouding. At this stage, it can be called cloud computing. Until then, it can only be called virtualization.
Cloud computing private and public
There are two types of cloud computing: one is a private cloud, and the other is a public cloud. Still others connect a private cloud with a public cloud as a hybrid cloud. For the time being, this is not the case.
Private Cloud: Deploy the virtualized and cloudized software in someone else's data center. Users using private cloud are often very rich, buy their own land to build a computer room, buy their own servers, and then let cloud vendors deploy themselves.
VMware, in addition to virtualization, has also launched cloud computing products and has earned a lot in the private cloud market.
Public cloud: With the virtualization and cloudization software deployed in the cloud vendor's own data center, users do not need to invest a lot. Just register an account and click on a web page to create a virtual computer.
For example, AWS is Amazon's public cloud; domestic Ali cloud, Tencent cloud, NetEase cloud and so on.
Why does Amazon do public clouds? We know that Amazon was originally an e-commerce company that is relatively large abroad. When it is doing e-commerce, it will surely encounter a scenario similar to double-eleven: at a certain moment everyone rushes to buy something.
When everyone is rushing to buy something, it needs special time flexibility and space flexibility. Because it can't always prepare all the resources, it is too wasteful. But also can not be prepared for nothing, looking at the double eleven so many users want to buy things can not board.
Therefore, when it takes two to eleven, it creates a large number of virtual computers to support the e-commerce application. After the double eleventh, these resources are released to do other things. So Amazon needs a cloud platform.
However, commercial virtualization software is really too expensive. Amazon cannot always give all the money it makes in e-commerce to virtualization vendors.
So Amazon based on the open source virtualization technology, as described above Xen or KVM, developed a set of their own cloud software. I did not expect Amazon's callers to become more and more cows, cloud platforms have become more and more cows.
Because its cloud platform needs to support its own e-commerce applications, while traditional cloud computing vendors are mostly IT vendors, almost no application of their own, so Amazon's cloud platform is more application-friendly, and quickly developed into the first brand of cloud computing Make a lot of money.
Before Amazon announced its cloud computing platform earnings report, people have speculated that Amazon e-commerce will make money and that the cloud will also make money. Later, when a financial report was released, it was found that it was not ordinary money making. Just last year, Amazon’s AWS revenue reached US$12.2 billion and operating profit was US$3.1 billion.
Cloud Computing Make Money and Feelings
The first place in the public cloud was awesome. The second place Rackspace was just too good. No way, this is the cruelty of the Internet industry, mostly winner-take-all mode. So if the second place is not the cloud computing industry, many people may not have heard of it.
The second place would like to think, I can not do but the boss how to do it? Open source it. As mentioned above, although Amazon uses open source virtualization technology, the cloudized code is closed source.
Many companies that want to do and can not do cloud platform can only look at Amazon to make big money. Rackspace made the source code public, and the entire industry could work together to make the platform work better. Brothers and all of you together, and fight with the boss.
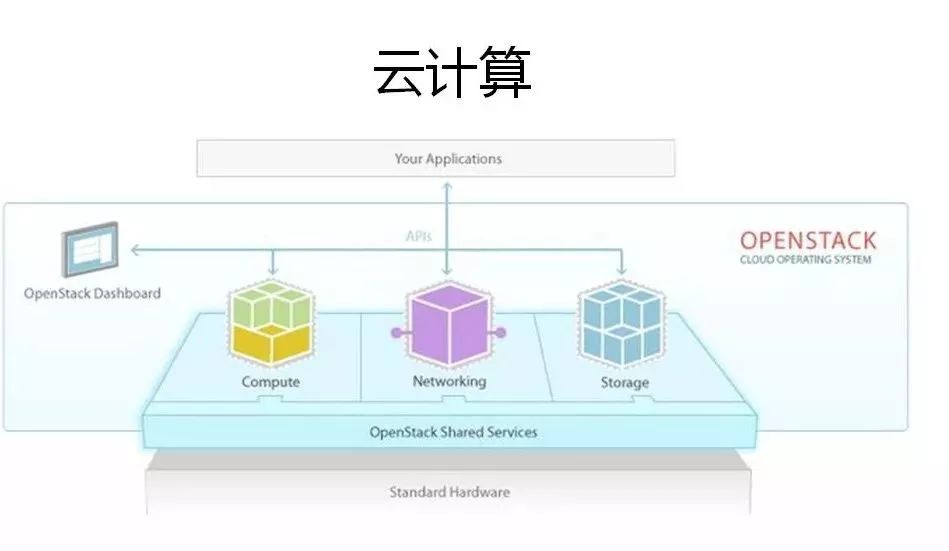
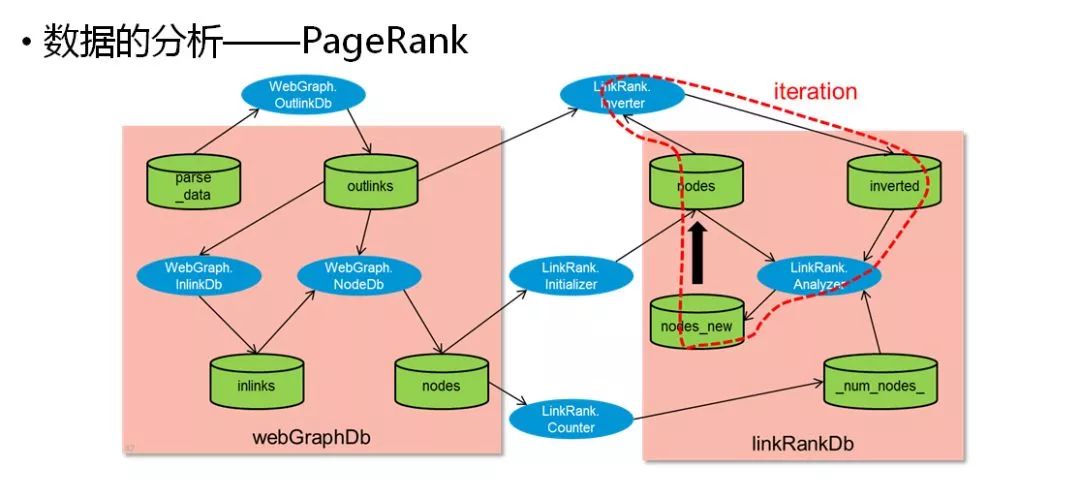
So Rackspace and NASA co-founded open-source software OpenStack. As shown in the figure above, the OpenStack architecture diagram is not for the cloud computing industry to understand this picture.
But you can see three keywords: Compute Computing, Networking Network, Storage Storage. It is also a cloud computing management platform for computing, network, and storage.
Of course, the second technology is also awesome. With OpenStack, as Rackspace thinks, all the big companies that want to do the cloud are crazy, you can imagine all the big IT companies: IBM, Hewlett-Packard, Dell, Huawei, Lenovo, etc. are all crazy.
The original cloud platform everyone wanted to do, watching Amazon and VMware made so much money, looked at no way, think of themselves as if it is quite difficult.
Well now, with such an open source cloud platform OpenStack, all IT vendors have joined the community, contributed to this cloud platform, packaged into their own products, and sold along with their own hardware devices.
Some have made private clouds, some have made public clouds, and OpenStack has become the de facto standard for open source cloud platforms.
IaaS, resource level flexibility
As the technology of OpenStack becomes more and more mature, it can be managed more and more, and there can be multiple deployments of multiple OpenStack clusters.
For example, one deployment in Beijing, two deployments in Hangzhou, and one deployment in Guangzhou, followed by unified management. So the whole scale is bigger.
At this scale, for the perception of ordinary users, it is basically able to do when and how much they want.
Or take the cloud disk as an example. Each user's cloud disk is allocated 5T or more space. If there are 100 million people, how much space does it add?
In fact, the underlying mechanism is this: To allocate your space, you may use only a few of them. For example, it allocates 5 T to you. Such a large space is just what you see, not really. For you.
In fact, you only use 50 G, then 50 G are true to you. With the continuous uploading of your files, more and more space will be allocated to you.
When everyone uploads, when the cloud platform is found to be almost full (for example, 70%), it will purchase more servers and expand the resources behind it. This is transparent and invisible to users.
Sensually speaking, the flexibility of cloud computing is realized. In fact, it is a bit like a bank. It gives depositors the feeling of when they need to withdraw money. As long as they do not run at the same time, banks will not be embarrassed.
to sum up
At this stage, cloud computing basically achieves time flexibility and space flexibility; it achieves flexibility in computing, network, and storage resources.
Computing, networking, and storage are often referred to as infrastructure Infranstracture. Therefore, the flexibility at this stage is called resource-level flexibility.
The cloud platform for managing resources, which we call infrastructure services, is the IaaS (Infranstracture As A Service) that we often hear.
Cloud computing is not only a resource but also an application
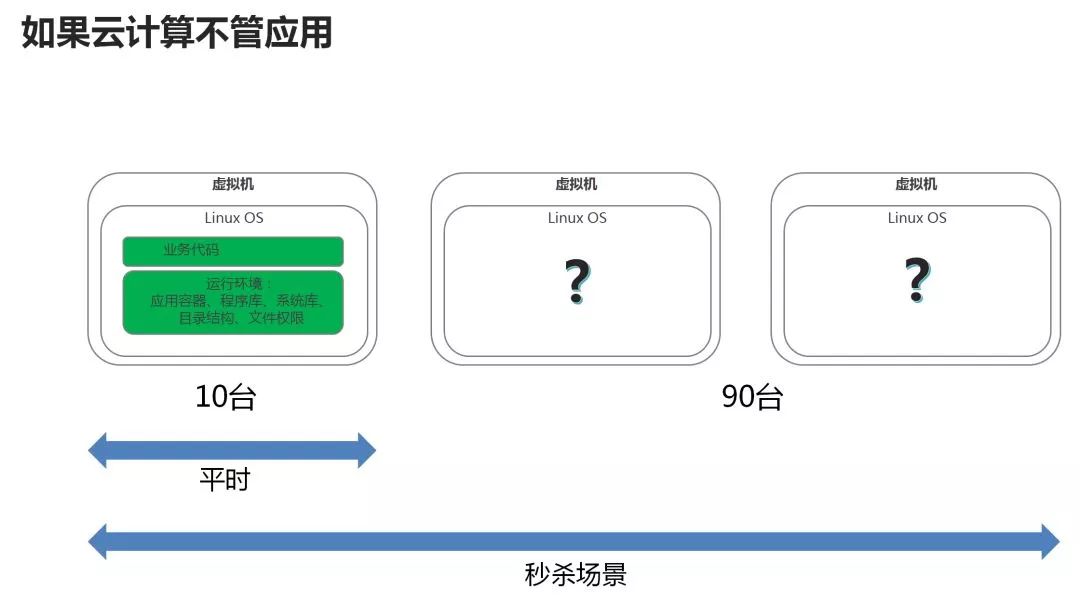
With IaaS, is it sufficient to achieve resiliency at the resource level? Obviously not, there is application-level flexibility.
Here's an example: For example, to implement an e-commerce application, ten machines are enough for the time being, and a double 11 needs 100 units. You may think it's easy to do. With IaaS, it will be possible to create 90 new machines.
However, the creation of 90 machines was empty, and the e-commerce application was not put up. Only the company's operation and maintenance personnel were able to get one at a time, which took a long time to install.
Although flexibility has been achieved at the resource level, there is no flexibility at the application level and flexibility is still not enough. Is there a way to solve this problem?
People added a layer on top of the IaaS platform to manage the elasticity of applications above the resources. This layer is usually called the Platform As A Service (PaaS).
This layer is often more difficult to understand, roughly divided into two parts: some of the author called "your own application automatically installed", part of the author called "universal application does not install."
Automatic installation of your own applications: For example, e-commerce applications are developed by you. Other than yourself, others do not know how to install them.
For e-commerce applications, the account of Alipay or WeChat needs to be configured during installation so that when someone else buys something from your e-commerce provider, the money is paid into your account. No one but you knows.
So the installation process platform can not help, but it can help you to do automation, you need to do some work, to integrate their own configuration information into the automated installation process.
For example, in the above example, the 90 new machines created by Double 11 are empty. If a tool can be provided to automatically install the e-commerce application on the new 90 machines, it will be able to achieve real flexibility at the application level. .
For example Puppet, Chef, Ansible, Cloud Foundary can do this thing, the latest container technology Docker can do this better.
The general application does not need to install: The so-called general application, generally refers to some high complexity, but everybody uses, for example the database. Almost all applications will use a database, but the database software is standard. Although installation and maintenance are more complicated, no matter who installs it, it is the same.
Such an application can become a standard PaaS layer application on the cloud platform interface. When the user needs a database, one point comes out and the user can use it directly.
Someone asked me, since whoever installs them is the same, then I've come to myself and I don't need to spend money to buy on the cloud platform. Of course not, the database is a very difficult thing, Oracle this company, can rely on the database to make so much money. Buying Oracle also costs a lot of money.
However, most cloud platforms will provide open source databases such as MySQL, which are open source. Money does not need to spend so much.
However, maintaining this database requires a large team of experts. If the database can be optimized to support Double Eleven, it is not a year or two.
For example, if you are a cyclist, you certainly don't need to recruit a very large database team to do it. The cost is too high. You should give it to the cloud platform to do this.
Professional people do professional things, and the cloud platform has specialized in maintaining hundreds of people to maintain this system. You just need to focus on your cycling application.
Either auto-deployment or no-deployment. In general, you have to worry about the application layer. This is the important role of the PaaS layer.
Although the script approach can solve the deployment problem of its own application, different environments are different. A script often runs correctly in one environment and is not correct in another environment.
The container is better able to solve this problem.
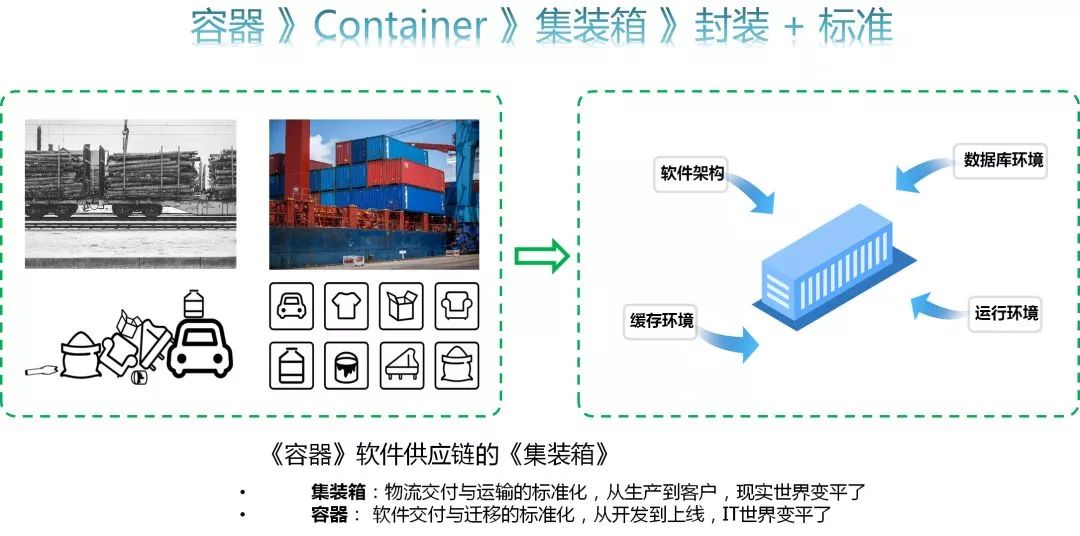
The container is a Container, Container another container, in fact, the idea of ​​the container is to become a container for software delivery. The characteristics of the container: First, the package, the second is the standard.

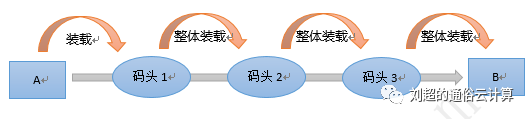
In the absence of containers, it was assumed that the goods would be shipped from A to B, with three terminals and three ships in the middle.
Every time the goods are unloaded, they are dropped, and then they are put on the boat and they are neatly arranged. Therefore, in the absence of a container, the crew must wait a few days on the shore before each change.
With containers, all the goods are packaged together, and the dimensions of the containers are all the same, so every time you change a ship, one box moves over the line, the hour level can be completed, and the crew no longer have to land ashore for long delays Now.
This is the application of two major characteristics of container "encapsulation" and "standard" in life.

How does the container package the application? Still have to learn containers. First of all, there must be a closed environment where the goods are packaged so that the goods do not interfere with each other and are isolated from one another. This makes loading and unloading convenient. Fortunately, LXC technology in Ubuntu has long been able to do this.
The closed environment mainly uses two technologies:
The technology that appears to be isolated is called a Namespace, which means that each application in the Namespace sees a different IP address, user space, and process number.
It is isolated technology, called Cgroups, which means that the entire machine has a lot of CPU and memory, and an application can only use a part of it.
The so-called mirror image is the moment you weld the container and save the state of the container. Just like the Monkey King said, “fixedâ€, the container is set at that moment, and then the state of the moment is saved as a series of documents.
The format of these files is standard, and anyone who sees these files can restore the time that they were staying. The process of restoring the image to the runtime (that is, reading the image file and restoring the time) is the process of the container running.
With containers, the automatic deployment of PaaS layers to the user's own applications becomes fast and elegant.
Big Data Embraces Cloud Computing
A complex general-purpose application in the PaaS layer is the big data platform. How is big data integrated into cloud computing step by step?
The data is not large but also contains wisdom
This big data is not big at the beginning. How much data did you have originally? Now everyone goes to the e-book and reads the news on the Internet. When we were young in 80s, the amount of information was not so great. Then we read books and read newspapers. How many words did a week's newspaper add up?
If you are not in a big city, the library of an ordinary school does not add up to several bookshelves. Later, with the arrival of information, there will be more and more information.
First of all, let's look at the data in big data. There are three types:
Structured data: data with a fixed format and limited length. For example, the completed form is structured data. Nationality: People’s Republic of China, Ethnicity: Han, Sex: Male. These are called structured data.
Unstructured data: More and more unstructured data is now available. It is data with variable length and no fixed format, such as web pages. Sometimes it is very long, and sometimes a few words are gone; for example, voice and video are not. Structured data.
Semi-structured data: It is in some XML or HTML format. It may not be technically unfamiliar but it does not matter.
In fact, the data itself is not useful and must go through some processing. For example, if you run with a bracelet every day, you collect data. So many web pages on the Internet are also data. We call it Data.
The data itself is useless, but the data contains a very important thing called information.
The data is very messy and can only be called information after combing and cleaning. Information can contain many laws. We need to sum up the laws from information, which is called knowledge, and knowledge changes fate.
There is a lot of information, but some people see the information is equivalent to the white look, but some people see the future of e-commerce from the information. Some people see the future of live broadcasting, so people are cattle.
If you do not extract knowledge from the information, watching friends circles every day can only be a spectator in the tide of the Internet.
With knowledge, and then using this knowledge to apply to actual combat, some people will do very well. This thing is called Intelligence.
Knowledge does not necessarily have wisdom. For example, many scholars are very knowledgeable. The things that have happened can be analyzed from various angles. However, if you do it, you can't turn it into wisdom.
The reason why many entrepreneurs are great is to apply their knowledge to practice and finally do a great deal of business.
So the application of data is divided into these four steps: data, information, knowledge, and wisdom.
The final stage is what many businesses want. You see that I have collected so much data. Can I use this data to help me make the next decision and improve my product?
For example, when a user watches a video, an advertisement pops up next to him, which is exactly what he wants to buy. Another example is when the user listens to music, he recommends other music that he would like to hear.
The user clicks a little mouse on my application or website. The input text is data for me. I just want to extract some of them, guide practice, and form wisdom, so that users can't get out of my application. On my network, I don't want to leave. I keep on hand and keep buying.
Many people said that I would like to break my net for the double eleventh. My wife bought and bought it on the top, bought A and recommended B, and his wife said, “Oh, B is what I like, my husband wants to buy it.â€
How do you say this program is so wise, so wise, knows my wife better than I am, how did this thing happen?

How data sublimates into wisdom
The processing of data is divided into the following steps. When it is completed, there will be wisdom in the end:
data collection
data transmission
data storage
Data Processing and Analysis
Data retrieval and mining
data collection
First of all, there is data. There are two ways to collect data:
Take, professional point of view is called grabbing or crawling. For example, a search engine does this: it downloads all the information on the Internet to its data center, and then you search it out.
For example, when you search, the result will be a list. Why is this list in the search engine company? It's because he took the data down, but you clicked on it, and clicking out of this site is no longer a search engine for the company.
For example, there is a Sina news, you get Baidu search out, when you do not point, that page in the Baidu data center, a little out of the page is in the Sina data center.
Push, there are many terminals that can help me collect data. For example, the millet bracelet can upload your daily running data, heart rate data, and sleep data to the data center.
data transmission
This is usually done through a queue because the amount of data is really too large and the data must be processed before it can be useful. But the system can not handle it, but had to queue up and slowly handle it.
data storage
Now that data is money, mastering the data is equivalent to having money. How else does the website know what you want to buy?
Because it has your historical transaction data, this information can not be given to others, it is very valuable, so it needs to be stored.
Data Processing and Analysis
The data stored above is the original data, the original data is mostly disorderly, there are a lot of garbage data in it, and therefore need to be cleaned and filtered to get some high-quality data.
For high-quality data, analysis can be performed to classify the data, or discover the interrelationships between the data and gain knowledge.
For example, the story of beer and diapers in the rumored Wal-Mart supermarket is to analyze people’s purchase data and discover that when men generally buy diapers, they will also buy beer.
In this way, the relationship between beer and diapers was discovered, knowledge was gained, and then applied to practice. The beer and diaper counters were brought close to each other and wisdom was gained.
Data retrieval and mining
Search is search, so-called foreign affairs asked Google, asked Baidu internal problems. Both internal and external search engines put the analyzed data into the search engine, so when people want to search for information, they will have a search.
The other is excavation. Searching alone can no longer meet people's needs. It also requires excavating mutual relations from information.
Such as financial search, when searching for a company's stock, the company's executives should also be excavated?
If you only search out the company's stock and find it particularly good, then you buy it. At that time, its executives issued a statement that is very unfavorable to the stock and fell the next day. Does this not harm the general public? Therefore, it is very important to mine the relationships in data through various algorithms to form a knowledge base.
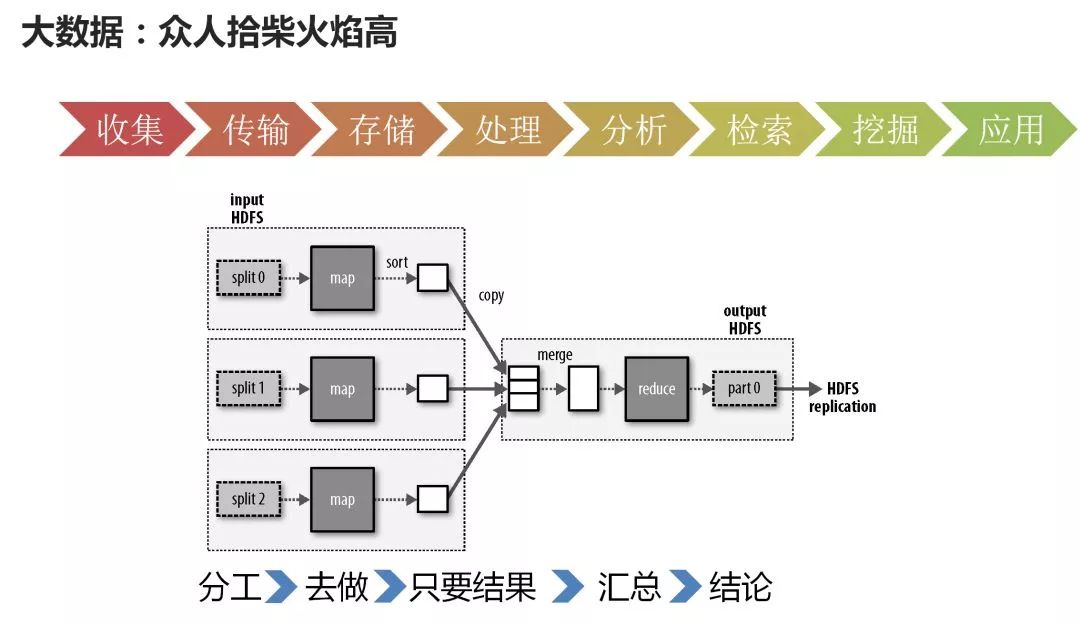
In the era of big data, everyone picks up firewood
When the amount of data is small, few machines can solve it. Slowly, when the amount of data is getting bigger and bigger, and the best server can't solve the problem, what should we do?
At this time, we must aggregate the power of multiple machines. We must all work together to get this thing together.
For data collection: As far as IoT is concerned, there are thousands of testing equipment deployed outside and a large amount of data such as temperature, humidity, monitoring, and power are collected; for the search engines of Internet web pages, the entire Internet needs to be All web pages are downloaded.
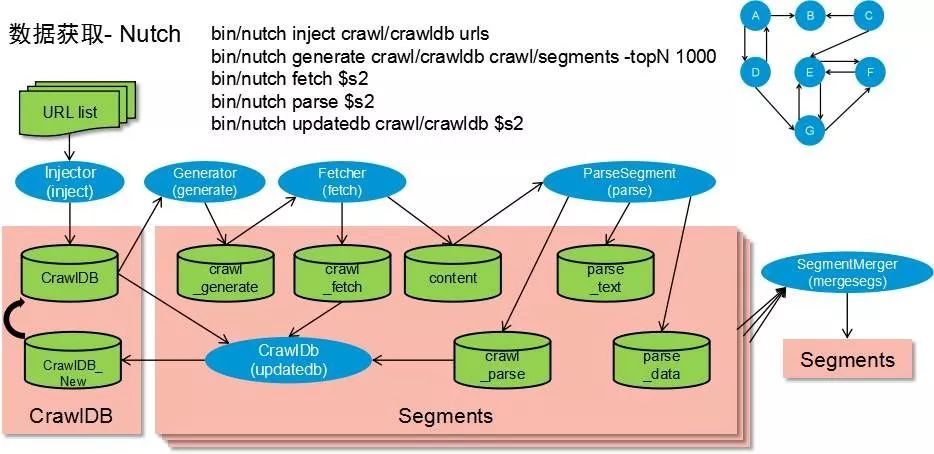
This obviously can't be done by a single machine. It requires multiple machines to form a web crawler system. Each machine downloads a part of it and works at the same time. Only in a limited amount of time can a huge amount of web pages be downloaded.
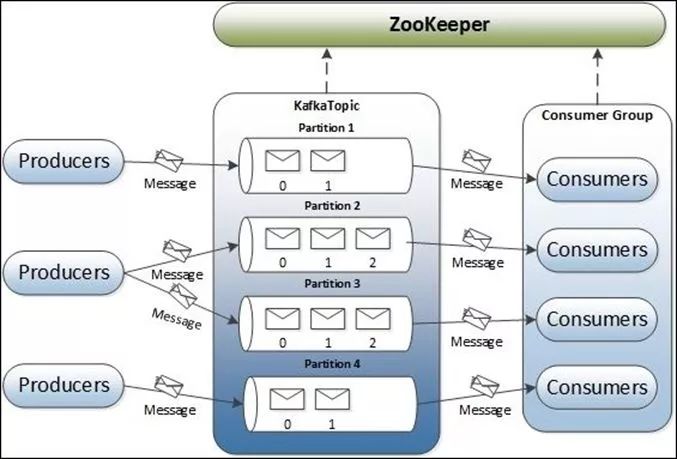
For the transmission of data: a queue in the memory will certainly be a lot of data burst out, so there is a hard disk-based distributed queue, so that the queue can be transmitted at the same time on more than one machine, depending on how much data you have, as long as my queue More than enough, the pipeline is thick enough to hold it.
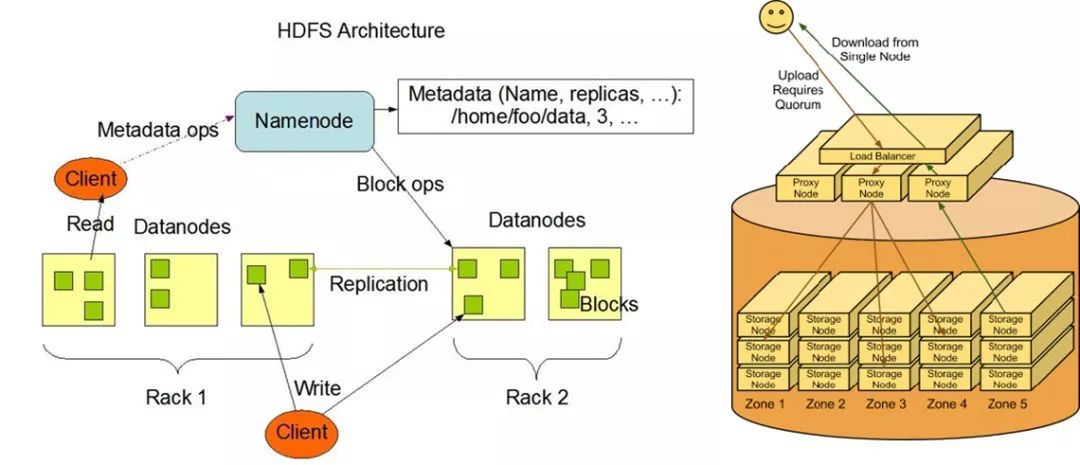
For data storage: a machine's file system is certainly not fit, so you need a large distributed file system to do this thing, the hard disk of multiple machines into a large file system.
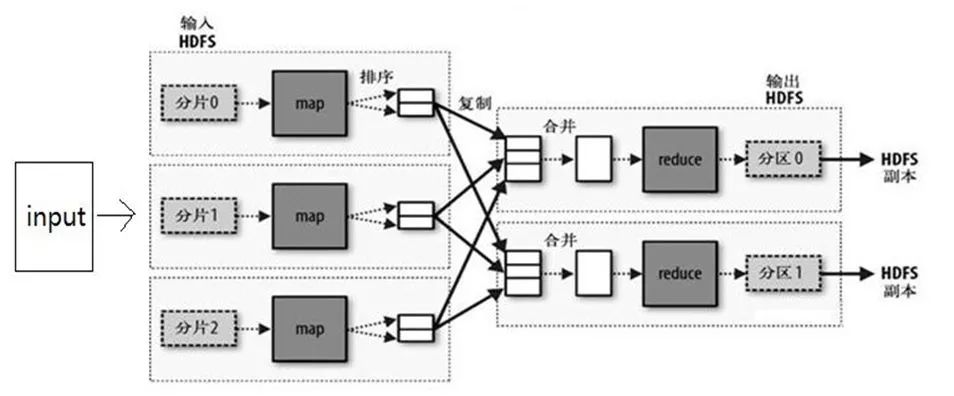
For the analysis of the data: It may be necessary to decompose, count, and summarize a large amount of data. One machine will surely be indefinite, and it will not be able to analyze the month of the monkey.
Then there is the distributed computing method, which divides a large amount of data into small portions. Each machine handles a small portion, and multiple machines are processed in parallel and can be calculated quickly.
For example, the well-known Terasort sorts one TB of data, which is equivalent to 1000G. If it is processed in a single machine, it will take several hours, but the parallel processing is completed in 209 seconds.
So what is big data? To put it plainly, one machine is not finished, and everyone does it together.
However, as the amount of data becomes larger and larger, many small companies need to deal with a considerable amount of data. What can these small companies do without such a large number of machines?
Big data needs cloud computing, cloud computing needs big data
Having said this, everyone thought of cloud computing. When you want to do these activities, you need a lot of machines to do it. When you really want to think about what you want and how much you want.
For example, the financial status of a big data analytics company may be analyzed once a week. If you want to put this hundred machines or one thousand machines all together, once a week is very wasteful.
Can it be necessary to calculate the time to take out the thousands of machines? When not counting, let the thousand machines do other things?
Who can do this thing? Only cloud computing can provide resource-level flexibility for big data operations.
Cloud computing also deploys big data to its PaaS platform as a very important universal application.
Because the big data platform can make multiple machines do things together, this thing is not something that the average person can develop, nor is the average person having fun. How can we have to hire a few dozen hundred people to play this.
So just like a database, you still need a bunch of professional people to play this thing. There is basically a big data solution on the public cloud.
When a small company needs a big data platform, it does not need to purchase a thousand machines. As long as it is on the public cloud, the thousands of machines are all out, and the big data platform has already been deployed. Just put the data into it. It's OK.
Cloud computing needs big data and big data needs cloud computing. The two are combined like this.
Artificial Intelligence Embraces Big Data
When will the machine understand the human heart?
Although there is big data, people's desires cannot be satisfied. Although there is a search engine in the big data platform, what you want to search for comes out.
但也å˜åœ¨è¿™æ ·çš„情况:我想è¦çš„东西ä¸ä¼šæœï¼Œè¡¨è¾¾ä¸å‡ºæ¥ï¼Œæœç´¢å‡ºæ¥çš„åˆä¸æ˜¯æˆ‘想è¦çš„。
例如音ä¹è½¯ä»¶æŽ¨è了一首æŒï¼Œè¿™é¦–æŒæˆ‘没å¬è¿‡ï¼Œå½“然ä¸çŸ¥é“åå—,也没法æœã€‚但是软件推è给我,我的确喜欢,这就是æœç´¢åšä¸åˆ°çš„事情。
当人们使用这ç§åº”用时,会å‘现机器知é“我想è¦ä»€ä¹ˆï¼Œè€Œä¸æ˜¯è¯´å½“我想è¦æ—¶ï¼ŒåŽ»æœºå™¨é‡Œé¢æœç´¢ã€‚这个机器真åƒæˆ‘的朋å‹ä¸€æ ·æ‡‚我,这就有点人工智能的æ„æ€äº†ã€‚
人们很早就在想这个事情了。最早的时候,人们想象,è¦æ˜¯æœ‰ä¸€å µå¢™ï¼Œå¢™åŽé¢æ˜¯ä¸ªæœºå™¨ï¼Œæˆ‘给它说è¯ï¼Œå®ƒå°±ç»™æˆ‘回应。
如果我感觉ä¸å‡ºå®ƒé‚£è¾¹æ˜¯äººè¿˜æ˜¯æœºå™¨ï¼Œé‚£å®ƒå°±çœŸçš„是一个人工智能的东西了。
让机器å¦ä¼šæŽ¨ç†
怎么æ‰èƒ½åšåˆ°è¿™ä¸€ç‚¹å‘¢ï¼Ÿäººä»¬å°±æƒ³ï¼šæˆ‘首先è¦å‘Šè¯‰è®¡ç®—机人类推ç†çš„èƒ½åŠ›ã€‚ä½ çœ‹äººé‡è¦çš„是什么?人和动物的区别在什么?就是能推ç†ã€‚
è¦æ˜¯æŠŠæˆ‘这个推ç†çš„èƒ½åŠ›å‘Šè¯‰æœºå™¨ï¼Œè®©æœºå™¨æ ¹æ®ä½ çš„æ问,推ç†å‡ºç›¸åº”的回ç”ï¼Œè¿™æ ·å¤šå¥½ï¼Ÿ
其实目å‰äººä»¬æ…¢æ…¢åœ°è®©æœºå™¨èƒ½å¤Ÿåšåˆ°ä¸€äº›æŽ¨ç†äº†ï¼Œä¾‹å¦‚è¯æ˜Žæ•°å¦å…¬å¼ã€‚这是一个éžå¸¸è®©äººæƒŠå–œçš„一个过程,机器竟然能够è¯æ˜Žæ•°å¦å…¬å¼ã€‚
但慢慢åˆå‘çŽ°è¿™ä¸ªç»“æžœä¹Ÿæ²¡æœ‰é‚£ä¹ˆä»¤äººæƒŠå–œã€‚å› ä¸ºå¤§å®¶å‘现了一个问题:数å¦å…¬å¼éžå¸¸ä¸¥è°¨ï¼ŒæŽ¨ç†è¿‡ç¨‹ä¹Ÿéžå¸¸ä¸¥è°¨ï¼Œè€Œä¸”æ•°å¦å…¬å¼å¾ˆå®¹æ˜“拿机器æ¥è¿›è¡Œè¡¨è¾¾ï¼Œç¨‹åºä¹Ÿç›¸å¯¹å®¹æ˜“表达。
然而人类的è¯è¨€å°±æ²¡è¿™ä¹ˆç®€å•äº†ã€‚æ¯”å¦‚ä»Šå¤©æ™šä¸Šï¼Œä½ å’Œä½ å¥³æœ‹å‹çº¦ä¼šï¼Œä½ 女朋å‹è¯´ï¼šå¦‚æžœä½ æ—©æ¥ï¼Œæˆ‘没æ¥ï¼Œä½ ç‰ç€ï¼›å¦‚果我早æ¥ï¼Œä½ 没æ¥ï¼Œä½ ç‰ç€ï¼
这个机器就比较难ç†è§£äº†ï¼Œä½†äººéƒ½æ‡‚ã€‚æ‰€ä»¥ä½ å’Œå¥³æœ‹å‹çº¦ä¼šï¼Œæ˜¯ä¸æ•¢è¿Ÿåˆ°çš„。
教给机器知识
å› æ¤ï¼Œä»…ä»…å‘Šè¯‰æœºå™¨ä¸¥æ ¼çš„æŽ¨ç†æ˜¯ä¸å¤Ÿçš„,还è¦å‘Šè¯‰æœºå™¨ä¸€äº›çŸ¥è¯†ã€‚但告诉机器知识这个事情,一般人å¯èƒ½å°±åšä¸æ¥äº†ã€‚å¯èƒ½ä¸“家å¯ä»¥ï¼Œæ¯”如è¯è¨€é¢†åŸŸçš„专家或者财ç»é¢†åŸŸçš„专家。
è¯è¨€é¢†åŸŸå’Œè´¢ç»é¢†åŸŸçŸ¥è¯†èƒ½ä¸èƒ½è¡¨ç¤ºæˆåƒæ•°å¦å…¬å¼ä¸€æ ·ç¨å¾®ä¸¥æ ¼ç‚¹å‘¢ï¼Ÿä¾‹å¦‚è¯è¨€ä¸“家å¯èƒ½ä¼šæ€»ç»“出主谓宾定状补这些è¯æ³•è§„则,主è¯åŽé¢ä¸€å®šæ˜¯è°“è¯ï¼Œè°“è¯åŽé¢ä¸€å®šæ˜¯å®¾è¯ï¼Œå°†è¿™äº›æ€»ç»“出æ¥ï¼Œå¹¶ä¸¥æ ¼è¡¨è¾¾å‡ºæ¥ä¸å°±è¡Œäº†å—?
åŽæ¥å‘现这个ä¸è¡Œï¼Œå¤ªéš¾æ€»ç»“了,è¯è¨€è¡¨è¾¾åƒå˜ä¸‡åŒ–。就拿主谓宾的例å,很多时候在å£è¯é‡Œé¢å°±çœç•¥äº†è°“è¯ï¼Œåˆ«äººé—®ï¼šä½ è°å•Šï¼Ÿæˆ‘回ç”:我刘超。
ä½†ä½ ä¸èƒ½è§„定在è¯éŸ³è¯ä¹‰è¯†åˆ«æ—¶ï¼Œè¦æ±‚对ç€æœºå™¨è¯´æ ‡å‡†çš„书é¢è¯ï¼Œè¿™æ ·è¿˜æ˜¯ä¸å¤Ÿæ™ºèƒ½ï¼Œå°±åƒç½—永浩在一次演讲ä¸è¯´çš„é‚£æ ·ï¼Œæ¯æ¬¡å¯¹ç€æ‰‹æœºï¼Œç”¨ä¹¦é¢è¯è¯´ï¼šè¯·å¸®æˆ‘呼å«æŸæŸæŸï¼Œè¿™æ˜¯ä¸€ä»¶å¾ˆå°´å°¬çš„事情。
人工智能这个阶段å«åšä¸“家系统。专家系统ä¸æ˜“æˆåŠŸï¼Œä¸€æ–¹é¢æ˜¯çŸ¥è¯†æ¯”较难总结,å¦ä¸€æ–¹é¢æ€»ç»“出æ¥çš„知识难以教给计算机。
å› ä¸ºä½ è‡ªå·±è¿˜è¿·è¿·ç³Šç³Šï¼Œè§‰å¾—ä¼¼ä¹Žæœ‰è§„å¾‹ï¼Œå°±æ˜¯è¯´ä¸å‡ºæ¥ï¼Œåˆæ€Žä¹ˆèƒ½å¤Ÿé€šè¿‡ç¼–程教给计算机呢?
算了,教ä¸ä¼šä½ 自己å¦å§
于是人们想到:机器是和人完全ä¸ä¸€æ ·çš„物ç§ï¼Œå¹²è„†è®©æœºå™¨è‡ªå·±å¦ä¹ 好了。
机器怎么å¦ä¹ 呢?既然机器的统计能力这么强,基于统计å¦ä¹ ,一定能从大é‡çš„æ•°å—ä¸å‘现一定的规律。
其实在娱ä¹åœˆæœ‰å¾ˆå¥½çš„一个例å,å¯çª¥ä¸€æ–‘:
有一ä½ç½‘å‹ç»Ÿè®¡äº†çŸ¥åæŒæ‰‹åœ¨å¤§é™†å‘行的9 å¼ ä¸“è¾‘ä¸117 首æŒæ›²çš„æŒè¯ï¼ŒåŒä¸€è¯è¯åœ¨ä¸€é¦–æŒå‡ºçŽ°åªç®—一次,形容è¯ã€åè¯å’ŒåŠ¨è¯çš„å‰åå如下表所示(è¯è¯åŽé¢çš„æ•°å—是出现的次数):
如果我们éšä¾¿å†™ä¸€ä¸²æ•°å—,然åŽæŒ‰ç…§æ•°ä½ä¾æ¬¡åœ¨å½¢å®¹è¯ã€åè¯å’ŒåŠ¨è¯ä¸å–出一个è¯ï¼Œè¿žåœ¨ä¸€èµ·ä¼šæ€Žä¹ˆæ ·å‘¢ï¼Ÿ
例如å–圆周率3.1415926,对应的è¯è¯æ˜¯ï¼šåšå¼ºï¼Œè·¯ï¼Œé£žï¼Œè‡ªç”±ï¼Œé›¨ï¼ŒåŸ‹ï¼Œè¿·æƒ˜ã€‚
ç¨å¾®è¿žæŽ¥å’Œæ¶¦è‰²ä¸€ä¸‹ï¼š
åšå¼ºçš„å©å
ä¾ç„¶å‰è¡Œåœ¨è·¯ä¸Š
å¼ å¼€ç¿…è†€é£žå‘自由
让雨水埋葬他的迷惘
是ä¸æ˜¯æœ‰ç‚¹æ„Ÿè§‰äº†ï¼Ÿå½“然,真æ£åŸºäºŽç»Ÿè®¡çš„å¦ä¹ 算法比这个简å•çš„统计å¤æ‚得多。
然而统计å¦ä¹ 比较容易ç†è§£ç®€å•çš„相关性:例如一个è¯å’Œå¦ä¸€ä¸ªè¯æ€»æ˜¯ä¸€èµ·å‡ºçŽ°ï¼Œä¸¤ä¸ªè¯åº”è¯¥æœ‰å…³ç³»ï¼›è€Œæ— æ³•è¡¨è¾¾å¤æ‚的相关性。
并且统计方法的公å¼å¾€å¾€éžå¸¸å¤æ‚,为了简化计算,常常åšå‡ºå„ç§ç‹¬ç«‹æ€§çš„å‡è®¾ï¼Œæ¥é™ä½Žå…¬å¼çš„计算难度,然而现实生活ä¸ï¼Œå…·æœ‰ç‹¬ç«‹æ€§çš„事件是相对较少的。
模拟大脑的工作方å¼
于是人类开始从机器的世界,åæ€äººç±»çš„世界是怎么工作的。

人类的脑å里é¢ä¸æ˜¯å˜å‚¨ç€å¤§é‡çš„规则,也ä¸æ˜¯è®°å½•ç€å¤§é‡çš„统计数æ®ï¼Œè€Œæ˜¯é€šè¿‡ç¥žç»å…ƒçš„触å‘实现的。
æ¯ä¸ªç¥žç»å…ƒæœ‰ä»Žå…¶ä»–神ç»å…ƒçš„输入,当接收到输入时,会产生一个输出æ¥åˆºæ¿€å…¶ä»–神ç»å…ƒã€‚于是大é‡çš„神ç»å…ƒç›¸äº’å应,最终形æˆå„ç§è¾“出的结果。
例如当人们看到美女瞳å”会放大,ç»ä¸æ˜¯å¤§è„‘æ ¹æ®èº«æ比例进行规则判æ–,也ä¸æ˜¯å°†äººç”Ÿä¸çœ‹è¿‡çš„所有的美女都统计一é,而是神ç»å…ƒä»Žè§†ç½‘膜触å‘到大脑å†å›žåˆ°çž³å”。
在这个过程ä¸ï¼Œå…¶å®žå¾ˆéš¾æ€»ç»“出æ¯ä¸ªç¥žç»å…ƒå¯¹æœ€ç»ˆçš„结果起到了哪些作用,åæ£å°±æ˜¯èµ·ä½œç”¨äº†ã€‚
于是人们开始用一个数å¦å•å…ƒæ¨¡æ‹Ÿç¥žç»å…ƒã€‚
这个神ç»å…ƒæœ‰è¾“入,有输出,输入和输出之间通过一个公å¼æ¥è¡¨ç¤ºï¼Œè¾“å…¥æ ¹æ®é‡è¦ç¨‹åº¦ä¸åŒ(æƒé‡),影å“ç€è¾“出。
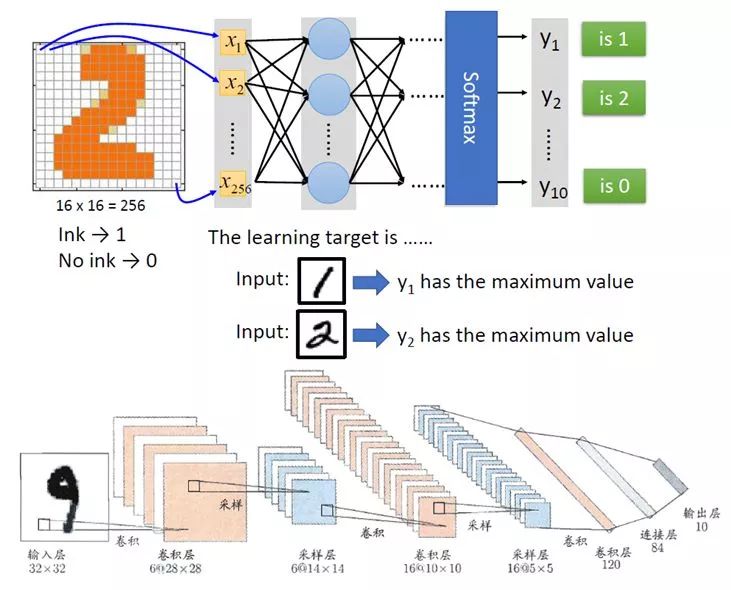
于是将n 个神ç»å…ƒé€šè¿‡åƒä¸€å¼ 神ç»ç½‘ç»œä¸€æ ·è¿žæŽ¥åœ¨ä¸€èµ·ã€‚n 这个数å—å¯ä»¥å¾ˆå¤§å¾ˆå¤§ï¼Œæ‰€æœ‰çš„神ç»å…ƒå¯ä»¥åˆ†æˆå¾ˆå¤šåˆ—,æ¯ä¸€åˆ—很多个排列起æ¥ã€‚
æ¯ä¸ªç¥žç»å…ƒå¯¹äºŽè¾“入的æƒé‡å¯ä»¥éƒ½ä¸ç›¸åŒï¼Œä»Žè€Œæ¯ä¸ªç¥žç»å…ƒçš„å…¬å¼ä¹Ÿä¸ç›¸åŒã€‚å½“äººä»¬ä»Žè¿™å¼ ç½‘ç»œä¸è¾“入一个东西的时候,希望输出一个对人类æ¥è®²æ£ç¡®çš„结果。
例如上é¢çš„例å,输入一个写ç€2 的图片,输出的列表里é¢ç¬¬äºŒä¸ªæ•°å—最大,其实从机器æ¥è®²ï¼Œå®ƒæ—¢ä¸çŸ¥é“输入的这个图片写的是2,也ä¸çŸ¥é“输出的这一系列数å—çš„æ„义,没关系,人知é“æ„义就å¯ä»¥äº†ã€‚
æ£å¦‚对于神ç»å…ƒæ¥è¯´ï¼Œä»–们既ä¸çŸ¥é“视网膜看到的是美女,也ä¸çŸ¥é“çž³å”放大是为了看的清楚,åæ£çœ‹åˆ°ç¾Žå¥³ï¼Œçž³å”放大了,就å¯ä»¥äº†ã€‚
å¯¹äºŽä»»ä½•ä¸€å¼ ç¥žç»ç½‘络,è°ä¹Ÿä¸æ•¢ä¿è¯è¾“入是2,输出一定是第二个数å—最大,è¦ä¿è¯è¿™ä¸ªç»“果,需è¦è®ç»ƒå’Œå¦ä¹ 。
毕竟看到美女而瞳å”放大也是人类很多年进化的结果。å¦ä¹ 的过程就是,输入大é‡çš„图片,如果结果ä¸æ˜¯æƒ³è¦çš„结果,则进行调整。
如何调整呢?就是æ¯ä¸ªç¥žç»å…ƒçš„æ¯ä¸ªæƒé‡éƒ½å‘ç›®æ ‡è¿›è¡Œå¾®è°ƒï¼Œç”±äºŽç¥žç»å…ƒå’Œæƒé‡å®žåœ¨æ˜¯å¤ªå¤šäº†ï¼Œæ‰€ä»¥æ•´å¼ 网络产生的结果很难表现出éžæ¤å³å½¼çš„结果,而是å‘ç€ç»“果微微地进æ¥ï¼Œæœ€ç»ˆèƒ½å¤Ÿè¾¾åˆ°ç›®æ ‡ç»“果。
当然,这些调整的ç–略还是éžå¸¸æœ‰æŠ€å·§çš„,需è¦ç®—法的高手æ¥ä»”细的调整。æ£å¦‚人类è§åˆ°ç¾Žå¥³ï¼Œçž³å”一开始没有放大到能看清楚,于是美女跟别人跑了,下次å¦ä¹ 的结果是瞳å”放大一点点,而ä¸æ˜¯æ”¾å¤§é¼»å”。
没é“ç†ä½†åšå¾—到
å¬èµ·æ¥ä¹Ÿæ²¡æœ‰é‚£ä¹ˆæœ‰é“ç†ï¼Œä½†çš„确能åšåˆ°ï¼Œå°±æ˜¯è¿™ä¹ˆä»»æ€§ï¼
神ç»ç½‘络的普é性定ç†æ˜¯è¿™æ ·è¯´çš„,å‡è®¾æŸä¸ªäººç»™ä½ æŸç§å¤æ‚奇特的函数,f(x):
ä¸ç®¡è¿™ä¸ªå‡½æ•°æ˜¯ä»€ä¹ˆæ ·çš„,总会确ä¿æœ‰ä¸ªç¥žç»ç½‘络能够对任何å¯èƒ½çš„输入x,其值f(x)(或者æŸä¸ªèƒ½å¤Ÿå‡†ç¡®çš„近似)是神ç»ç½‘络的输出。
如果在函数代表ç€è§„律,也æ„味ç€è¿™ä¸ªè§„å¾‹æ— è®ºå¤šä¹ˆå¥‡å¦™ï¼Œå¤šä¹ˆä¸èƒ½ç†è§£ï¼Œéƒ½æ˜¯èƒ½é€šè¿‡å¤§é‡çš„神ç»å…ƒï¼Œé€šè¿‡å¤§é‡æƒé‡çš„调整,表示出æ¥çš„。
人工智能的ç»æµŽå¦è§£é‡Š
这让我想到了ç»æµŽå¦ï¼ŒäºŽæ˜¯æ¯”较容易ç†è§£äº†ã€‚

我们把æ¯ä¸ªç¥žç»å…ƒå½“æˆç¤¾ä¼šä¸ä»Žäº‹ç»æµŽæ´»åŠ¨çš„个体。于是神ç»ç½‘络相当于整个ç»æµŽç¤¾ä¼šï¼Œæ¯ä¸ªç¥žç»å…ƒå¯¹äºŽç¤¾ä¼šçš„输入,都有æƒé‡çš„调整,åšå‡ºç›¸åº”的输出。
比如工资涨了ã€èœä»·æ¶¨äº†ã€è‚¡ç¥¨è·Œäº†ï¼Œæˆ‘应该怎么办ã€æ€Žä¹ˆèŠ±è‡ªå·±çš„钱。这里é¢æ²¡æœ‰è§„律么?肯定有,但是具体什么规律呢?很难说清楚。
基于专家系统的ç»æµŽå±žäºŽè®¡åˆ’ç»æµŽã€‚整个ç»æµŽè§„律的表示ä¸å¸Œæœ›é€šè¿‡æ¯ä¸ªç»æµŽä¸ªä½“的独立决ç–表现出æ¥ï¼Œè€Œæ˜¯å¸Œæœ›é€šè¿‡ä¸“家的高屋建瓴和远è§å“识总结出æ¥ã€‚但专家永远ä¸å¯èƒ½çŸ¥é“哪个城市的哪个街é“缺少一个å–甜豆è…脑的。
于是专家说应该产多少钢é“ã€äº§å¤šå°‘馒头,往往è·ç¦»äººæ°‘生活的真æ£éœ€æ±‚有较大的差è·ï¼Œå°±ç®—æ•´ä¸ªè®¡åˆ’ä¹¦å†™ä¸ªå‡ ç™¾é¡µï¼Œä¹Ÿæ— æ³•è¡¨è¾¾éšè—在人民生活ä¸çš„å°è§„律。
基于统计的å®è§‚调控就é 谱多了,æ¯å¹´ç»Ÿè®¡å±€éƒ½ä¼šç»Ÿè®¡æ•´ä¸ªç¤¾ä¼šçš„就业率ã€é€šèƒ€çŽ‡ã€GDP ç‰æŒ‡æ ‡ã€‚è¿™äº›æŒ‡æ ‡å¾€å¾€ä»£è¡¨ç€å¾ˆå¤šå†…在规律,虽然ä¸èƒ½ç²¾ç¡®è¡¨è¾¾ï¼Œä½†æ˜¯ç›¸å¯¹é 谱。
然而基于统计的规律总结表达相对比较粗糙。比如ç»æµŽå¦å®¶çœ‹åˆ°è¿™äº›ç»Ÿè®¡æ•°æ®ï¼Œå¯ä»¥æ€»ç»“出长期æ¥çœ‹æˆ¿ä»·æ˜¯æ¶¨è¿˜æ˜¯è·Œã€è‚¡ç¥¨é•¿æœŸæ¥çœ‹æ˜¯æ¶¨è¿˜æ˜¯è·Œã€‚
如果ç»æµŽæ€»ä½“上扬,房价和股票应该都是涨的。但基于统计数æ®ï¼Œæ— 法总结出股票,物价的微å°æ³¢åŠ¨è§„律。
基于神ç»ç½‘络的微观ç»æµŽå¦æ‰æ˜¯å¯¹æ•´ä¸ªç»æµŽè§„律最最准确的表达,æ¯ä¸ªäººå¯¹äºŽè‡ªå·±åœ¨ç¤¾ä¼šä¸çš„输入进行å„自的调整,并且调整åŒæ ·ä¼šä½œä¸ºè¾“å…¥å馈到社会ä¸ã€‚
想象一下股市行情细微的波动曲线,æ£æ˜¯æ¯ä¸ªç‹¬ç«‹çš„个体å„自ä¸æ–交易的结果,没有统一的规律å¯å¾ªã€‚
而æ¯ä¸ªäººæ ¹æ®æ•´ä¸ªç¤¾ä¼šçš„输入进行独立决ç–,当æŸäº›å› ç´ ç»è¿‡å¤šæ¬¡è®ç»ƒï¼Œä¹Ÿä¼šå½¢æˆå®è§‚上统计性的规律,这也就是å®è§‚ç»æµŽå¦æ‰€èƒ½çœ‹åˆ°çš„。
例如æ¯æ¬¡è´§å¸å¤§é‡å‘行,最åŽæˆ¿ä»·éƒ½ä¼šä¸Šæ¶¨ï¼Œå¤šæ¬¡è®ç»ƒåŽï¼Œäººä»¬ä¹Ÿå°±éƒ½å¦ä¼šäº†ã€‚
人工智能需è¦å¤§æ•°æ®
然而,神ç»ç½‘络包å«è¿™ä¹ˆå¤šçš„节点,æ¯ä¸ªèŠ‚点åˆåŒ…å«éžå¸¸å¤šçš„å‚数,整个å‚æ•°é‡å®žåœ¨æ˜¯å¤ªå¤§äº†ï¼Œéœ€è¦çš„计算é‡å®žåœ¨å¤ªå¤§ã€‚
但没有关系,我们有大数æ®å¹³å°ï¼Œå¯ä»¥æ±‡èšå¤šå°æœºå™¨çš„力é‡ä¸€èµ·æ¥è®¡ç®—,就能在有é™çš„时间内得到想è¦çš„结果。
人工智能å¯ä»¥åšçš„事情éžå¸¸å¤šï¼Œä¾‹å¦‚å¯ä»¥é‰´åˆ«åžƒåœ¾é‚®ä»¶ã€é‰´åˆ«é»„色暴力文å—和图片ç‰ã€‚
这也是ç»åŽ†äº†ä¸‰ä¸ªé˜¶æ®µçš„:
ä¾èµ–于关键è¯é»‘白åå•å’Œè¿‡æ»¤æŠ€æœ¯ï¼ŒåŒ…å«å“ªäº›è¯å°±æ˜¯é»„色或者暴力的文å—。éšç€è¿™ä¸ªç½‘络è¯è¨€è¶Šæ¥è¶Šå¤šï¼Œè¯ä¹Ÿä¸æ–地å˜åŒ–,ä¸æ–地更新这个è¯åº“就有点顾ä¸è¿‡æ¥ã€‚
基于一些新的算法,比如说è´å¶æ–¯è¿‡æ»¤ç‰ï¼Œä½ ä¸ç”¨ç®¡è´å¶æ–¯ç®—法是什么,但是这个åå—ä½ åº”è¯¥å¬è¿‡ï¼Œè¿™æ˜¯ä¸€ä¸ªåŸºäºŽæ¦‚率的算法。
基于大数æ®å’Œäººå·¥æ™ºèƒ½ï¼Œè¿›è¡Œæ›´åŠ 精准的用户画åƒã€æ–‡æœ¬ç†è§£å’Œå›¾åƒç†è§£ã€‚
由于人工智能算法多是ä¾èµ–于大é‡çš„æ•°æ®çš„,这些数æ®å¾€å¾€éœ€è¦é¢å‘æŸä¸ªç‰¹å®šçš„领域(例如电商,邮箱)进行长期的积累。
如果没有数æ®ï¼Œå°±ç®—有人工智能算法也白æ,所以人工智能程åºå¾ˆå°‘åƒå‰é¢çš„IaaS å’ŒPaaS ä¸€æ ·ï¼Œå°†äººå·¥æ™ºèƒ½ç¨‹åºç»™æŸä¸ªå®¢æˆ·å®‰è£…一套,让客户去用。
å› ä¸ºç»™æŸä¸ªå®¢æˆ·å•ç‹¬å®‰è£…一套,客户没有相关的数æ®åšè®ç»ƒï¼Œç»“果往往是很差的。
但云计算厂商往往是积累了大é‡æ•°æ®çš„,于是就在云计算厂商里é¢å®‰è£…一套,暴露一个æœåŠ¡æŽ¥å£ã€‚
比如您想鉴别一个文本是ä¸æ˜¯æ¶‰åŠé»„色和暴力,直接用这个在线æœåŠ¡å°±å¯ä»¥äº†ã€‚è¿™ç§å½¢åŠ¿çš„æœåŠ¡ï¼Œåœ¨äº‘计算里é¢ç§°ä¸ºè½¯ä»¶å³æœåŠ¡ï¼ŒSaaS (Software AS A Service)
于是工智能程åºä½œä¸ºSaaS å¹³å°è¿›å…¥äº†äº‘计算。
基于三者关系的美好生活
终于云计算的三兄弟凑é½äº†ï¼Œåˆ†åˆ«æ˜¯IaaSã€PaaS å’ŒSaaS。所以一般在一个云计算平å°ä¸Šï¼Œäº‘ã€å¤§æ•°æ®ã€äººå·¥æ™ºèƒ½éƒ½èƒ½æ‰¾å¾—到。
一个大数æ®å…¬å¸ï¼Œç§¯ç´¯äº†å¤§é‡çš„æ•°æ®ï¼Œä¼šä½¿ç”¨ä¸€äº›äººå·¥æ™ºèƒ½çš„算法æ供一些æœåŠ¡ï¼›ä¸€ä¸ªäººå·¥æ™ºèƒ½å…¬å¸ï¼Œä¹Ÿä¸å¯èƒ½æ²¡æœ‰å¤§æ•°æ®å¹³å°æ”¯æ’‘。
所以,当云计算ã€å¤§æ•°æ®ã€äººå·¥æ™ºèƒ½è¿™æ ·æ•´åˆèµ·æ¥ï¼Œä¾¿å®Œæˆäº†ç›¸é‡ã€ç›¸è¯†ã€ç›¸çŸ¥çš„过程。
Bitmain Antminer Asic Miner:Bitmain Antminer Z15,Bitmain Antminer Z9 Mini,Bitmain Antminer Z9,Bitmain Antminer Z11
Bitmain is the world's leading digital currency mining machine manufacturer. Its brand ANTMINER has maintained a long-term technological and market dominance in the industry, with customers covering more than 100 countries and regions. The company has subsidiaries in China, the United States, Singapore, Malaysia, Kazakhstan and other places.
Bitmain has a unique computing power efficiency ratio technology to provide the global blockchain network with outstanding computing power infrastructure and solutions. Since its establishment in 2013, ANTMINER BTC mining machine single computing power has increased by three orders of magnitude, while computing power efficiency ratio has decreased by two orders of magnitude. Bitmain's vision is to make the digital world a better place for mankind.
Bitmain Antminer Asic Miner,Z15 bitmain antminer,Z11 Antminer Bitmain,zcash miner,zec mining machine
Shenzhen YLHM Technology Co., Ltd. , https://www.asicminer-ylhm.com